In the last part, we saw our pipeline at the end. Steps 1-5 deal with data manipulation. We train our model in step 6 and that’s where MLflow comes into picture.
|
|
MLflow #
MLflow is an open source platform for managing the end-to-end machine learning lifecycle. It tackles four primary functions:
Tracking experiments to record and compare parameters and results (MLflow Tracking).
Packaging ML code in a reusable, reproducible form in order to share with other data scientists or transfer to production (MLflow Projects).
Managing and deploying models from a variety of ML libraries to a variety of model serving and inference platforms (MLflow Models).
Providing a central model store to collaboratively manage the full lifecycle of an MLflow Model, including model versioning, stage transitions, and annotations (MLflow Model Registry).
For our usecase, we mainly focus on Mlflow Tracking and Mlflow Registry.
train_clf() internally calls train_and_validate_clf() located at mlops/ml_workflow/naive_bayes_clf.py.
This script has as all the MLflow components and we will look at those in detail.
Tracking #
|
|
MLflow runs can be recorded to local files, to a SQLAlchemy compatible database, or remotely to a tracking server. By default, the MLflow Python API logs runs locally to files in an mlruns directory wherever you ran your program. You can then run mlflow ui to see the logged runs.
To log runs remotely, set the MLFLOW_TRACKING_URI environment variable to a tracking server’s URI or call mlflow.set_tracking_uri().
There are different kinds of remote tracking URIs:
- Local file path (specified as file:/my/local/dir), where data is just directly stored locally.
- Database encoded as
<dialect>+<driver>://<username>:<password>@<host>:<port>/<database>. MLflow supports the dialects mysql, mssql, sqlite, and postgresql. For more details, see SQLAlchemy database uri.- HTTP server (specified as https://my-server:5000), which is a server hosting an MLflow tracking server.
- Databricks workspace (specified as databricks or as
databricks://<profileName>, a Databricks CLI profile. Refer to Access the MLflow tracking server from outside Databricks [AWS] [Azure], or the quickstart to easily get started with hosted MLflow on Databricks Community Edition.
We use sqlite for tracking. MLFLOW_TRACKING_URI=sqlite:///mlflow.db.
This file stays at the root directory of the project.
You can optionally organize runs into experiments, which group together runs for a specific task. You can create an experiment using the mlflow experiments CLI, with mlflow.create_experiment(), or using the corresponding REST parameters. The MLflow API and UI let you create and search for experiments.
|
|
First time we execute the pipeline, experiment MLFLOW_EXPERIMENT_NAME=MLOps is
created and is used for subsequent runs.
|
|
Registry #
Under an experiment, we can log metrics, log model parameters, save and version
model artifacts.
These steps come under the purview of model-registry.
Here, we log
- classifier parameter
alpha - classification metrics
precision,recallandf1_score
We also save and version the model using mlflow.sklearn.log_model.
Each subsequent run of the pipeline with the same artifact_path and
registered_model_name increases the model version by 1 in the registry.
|
|
Heading over to the experiment section at http://127.0.0.1:5000, we can see
the registry entry for each of our runs, along with the logged metrics and
model parameters.
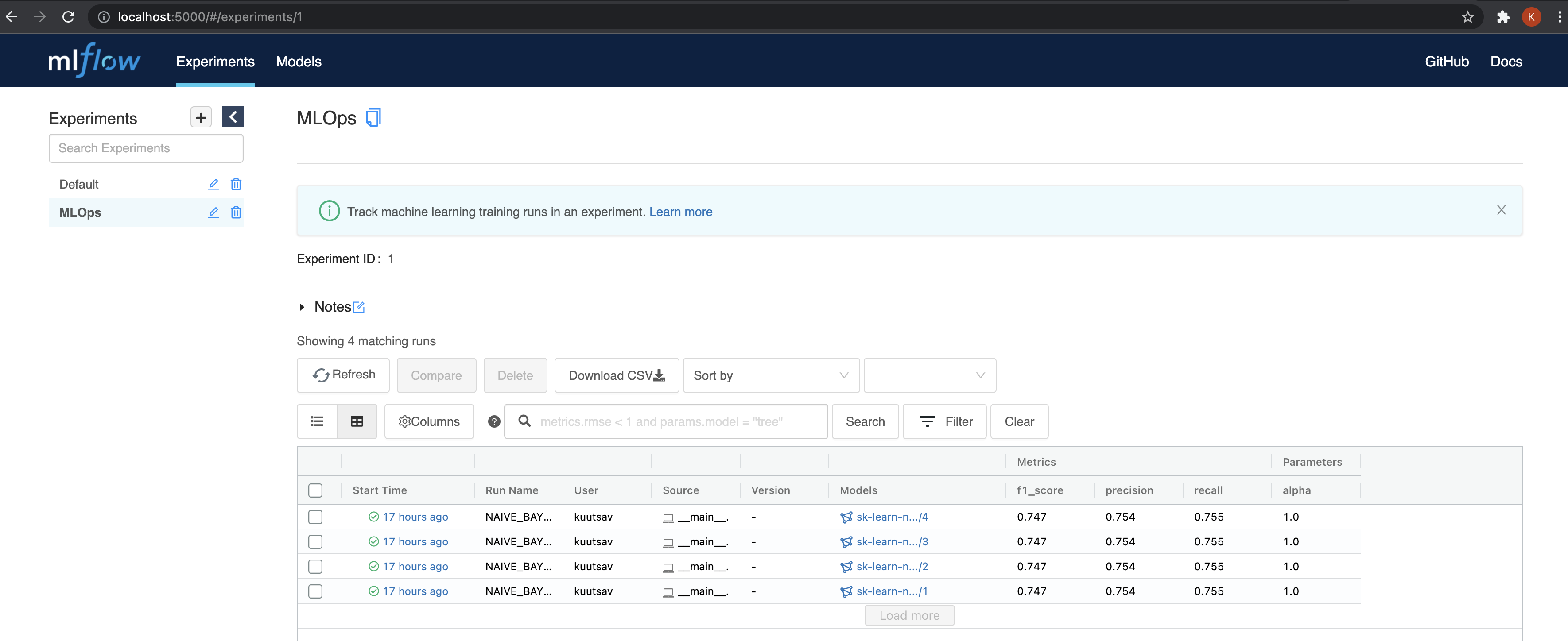
For each run, we can also look at the artifact location.
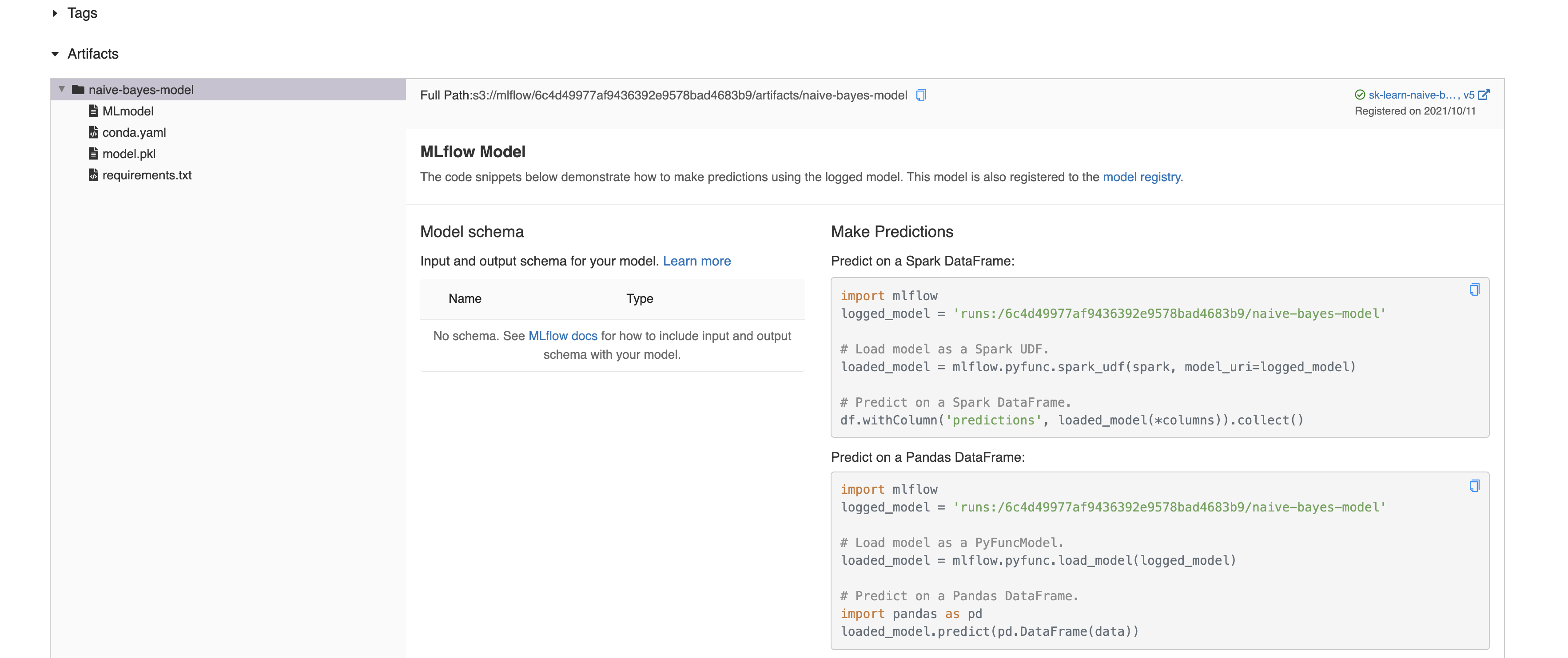
When we created the experiment, we speficified
artifact_location=os.getenv("MLFLOW_ARTIFACT_LOCATION") where
MLFLOW_ARTIFACT_LOCATION=s3://mlflow. Internally, this stores the
model artifacts locally at the directory minio_data we created during the
setup.
We can head over to http://127.0.0.1:9001/buckets/mlflow/browse to look at
the saved model artifacts.
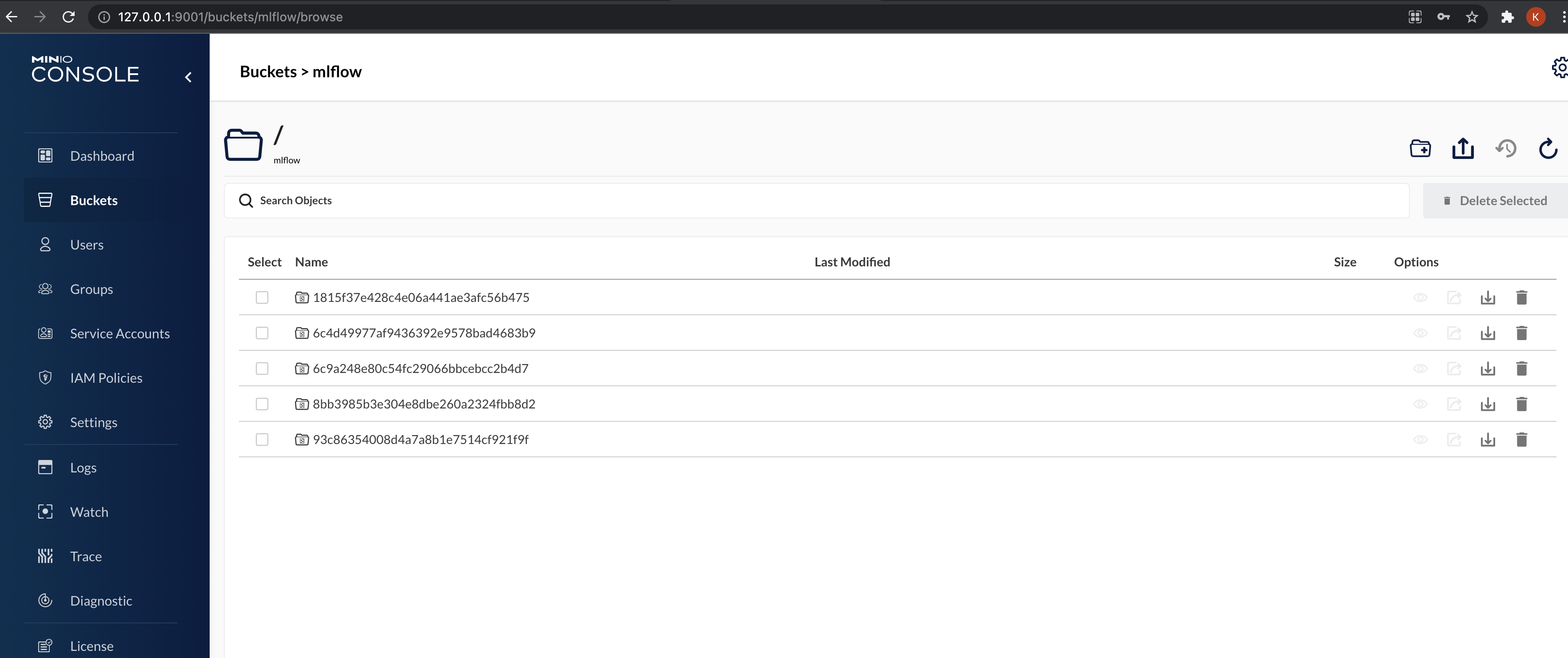
In the next part, we will look at serving the trained model being a REST endpoint.