One of the best things about python is it’s consistency. Once someone has spent enough time with python and it’s ecosystem, they tend to adapt easily to new tools, modules as long as they are written in a pythonic way.
What is considered pythonic is a very subjective matter, but we can always look at the “Zen of Python” for some guidance.
|
|
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Special Methods (dunder methods)
The heart of what makes an object pythonic is the Python Data Model. Python Data Model provides apis that help us create consistent behavior for our python objects. We achieve this consistency by adding special methods called dunder methods(or double underscore methods) to our objects.
Before looking into dunder methods, lets look at a simple object to demonstrate a point about python objects and the consistency we keep talking about.
Typically in Object Oriented Design we define a class which encapsulates some data and the associated methods that act on the data.
Suppose we have an object which internally maintains a collection and we want to know the length of the collection, typically the OOO design will go something like
MyObject.len()
or
MyObject.size()
...
whether it’s len(), length(), size() or something else is the choice of the designer of this API and the
users need to read the documentation/specification before using the object.
In python, we do this by calling len(MyObject). Now this is not a typical OOP behaviour, but this is what
is magical about python. Under the hood, len() refers to the __len__ dunder method of the object.
By adding these special methods to our class definition, we can provide consistent behaviour to our objects
so that new users can start using them easily and in a predictable manner(as long as they expect this behaviour).
Python has many more dunder methods. These methods provide a framework for building almost everything in python, be it iterators, collections, string representations, classes, coroutines, etc.
Let’s look at more dunder methods using the following example
|
|
|
|
36
|
|
DiePair(die1=2, die2=5)
Beyond indexing, by adding __getitem__ we get to access to other features like slicing
|
|
[DiePair(die1=1, die2=1),
DiePair(die1=1, die2=2),
DiePair(die1=1, die2=3),
DiePair(die1=1, die2=4),
DiePair(die1=1, die2=5)]
|
|
[DiePair(die1=6, die2=2),
DiePair(die1=6, die2=3),
DiePair(die1=6, die2=4),
DiePair(die1=6, die2=5),
DiePair(die1=6, die2=6)]
Our object two_dies is also an iterable now
|
|
DiePair(die1=1, die2=1)
DiePair(die1=1, die2=2)
DiePair(die1=1, die2=3)
DiePair(die1=1, die2=4)
DiePair(die1=1, die2=5)
DiePair(die1=1, die2=6)
DiePair(die1=2, die2=1)
DiePair(die1=2, die2=2)
DiePair(die1=2, die2=3)
...
Iteration is often implicit, for example
|
|
True
|
|
False
Both the above example work without the __contains__ dunder method in our class. In it’s
absence, the in operator does a sequential scan.
We can use built in modules to add methods like roll() to our class.
|
|
DiePair(die1=3, die2=1)
We can also sort the dies in reverse order based on die2.
|
|
[DiePair(die1=1, die2=6),
DiePair(die1=2, die2=6),
DiePair(die1=3, die2=6),
DiePair(die1=4, die2=6),
DiePair(die1=5, die2=6),
DiePair(die1=6, die2=6),
DiePair(die1=1, die2=5),
DiePair(die1=2, die2=5),
DiePair(die1=3, die2=5),
...]
All this is possible because of __getitem__ which makes our object behave like a python collection.
Dunder methods are not called directly by the user, but internally by the interpreter, except in special
cases like metaprogramming or in the __init__ of a class to initialize the base class it’s deriving from.
That does not mean we can’t invoke them explicitly.
|
|
36
More uses of dunder methods
Dunder methods have lots of other uses as well. For example
- Emulating numeric types(operator overloading)
- String representation for objects
Emulating Numeric Types
Let’s create a class that allows us to create vectors we use in physics or to represent data.
|
|
By adding __add__ and __mul__ special methods, we can start adding two vectors and multiplying scalars
to our vectors like we expect.
|
|
|
|
Vector(11, 5)
|
|
Vector(30, 9)
|
|
5.0
String representation of objects
The __repr__ method allows us to create a string representation for the object. This is
useful for debugging/logging purposes. If possible, it should return a string that describes
exactly how the object is created.
|
|
Vector(1, 2)
|
|
Vector(10, 3)
We also have a __str__ method that returns a string describing the object. Typically this is a
description of the object for the end user.
When the __repr__ is descriptive enough, the __str__ method can be avoided as it defaults to __repr__.
From stackoverflow:
My rule of thumb: repr is for developers, str is for customers.
Collection API
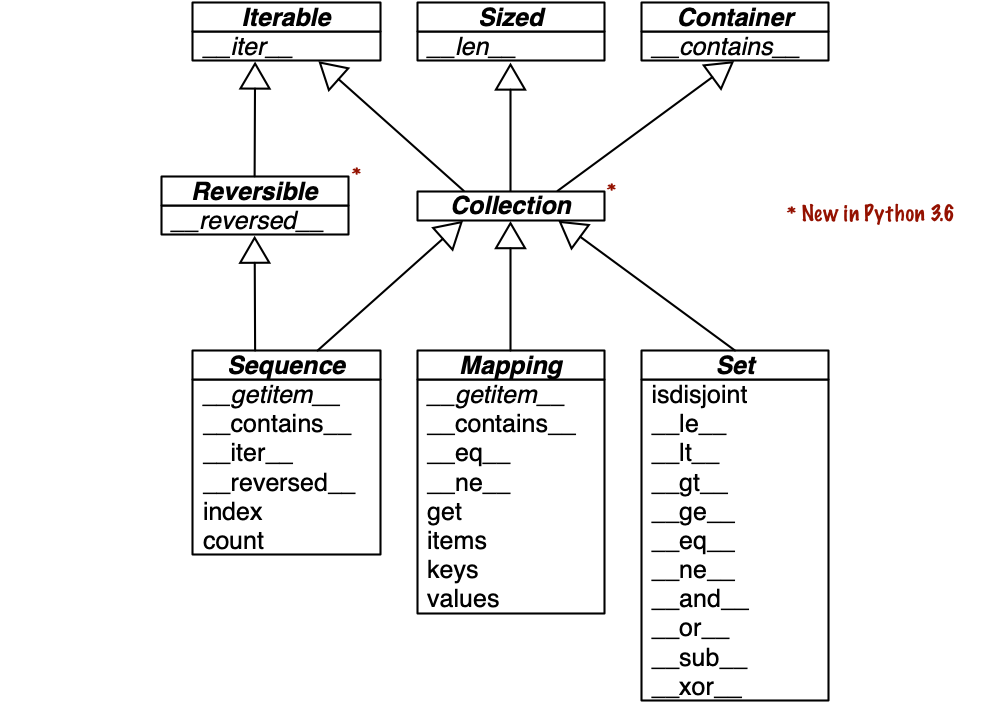
The UML diagram shows the three essential interface every collection should implement
- Iterable
- Sized
- Container
Three very important specializations of collection are
- Sequence: formalizing the interface of built-ins like list and str;
- Mapping: implemented by dict, collections.defaultdict, etc.;
- Set: the interface of the set and frozenset built-in types.
For example, let’s create a list
|
|
['__add__',
'__class__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__gt__',
'__hash__',
'__iadd__',
'__imul__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__len__',
'__lt__',
'__mul__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__reversed__',
'__rmul__',
'__setattr__',
'__setitem__',
'__sizeof__',
'__str__',
'__subclasshook__',
'append',
'clear',
'copy',
'count',
'extend',
'index',
'insert',
'pop',
'remove',
'reverse',
'sort']
The dir() method shows all the methods and special methods available for an object.
Here we can see all the essential interfacs as well as others. The built in python collections
implement these special methods for us.
Let’s look at a set now.
|
|
['__and__',
'__class__',
'__contains__',
'__delattr__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__gt__',
'__hash__',
'__iand__',
'__init__',
'__init_subclass__',
'__ior__',
'__isub__',
'__iter__',
'__ixor__',
'__le__',
'__len__',
'__lt__',
'__ne__',
'__new__',
'__or__',
'__rand__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__ror__',
'__rsub__',
'__rxor__',
'__setattr__',
'__sizeof__',
'__str__',
'__sub__',
'__subclasshook__',
'__xor__',
'add',
'clear',
'copy',
'difference',
'difference_update',
'discard',
'intersection',
'intersection_update',
'isdisjoint',
'issubset',
'issuperset',
'pop',
'remove',
'symmetric_difference',
'symmetric_difference_update',
'union',
'update']
|
|
{3}
We are able to do the above operation because of the special method __sub__ that’s been provided to us
by default.
References
[1] Luciano Ramalho. “Fluent Python”.