Given a set of N objects that support the following two commands:
Union: Connect two objects.
Find/Connected: Is there a path connecting the two obejcts?
For example, consider this set of 10 objects
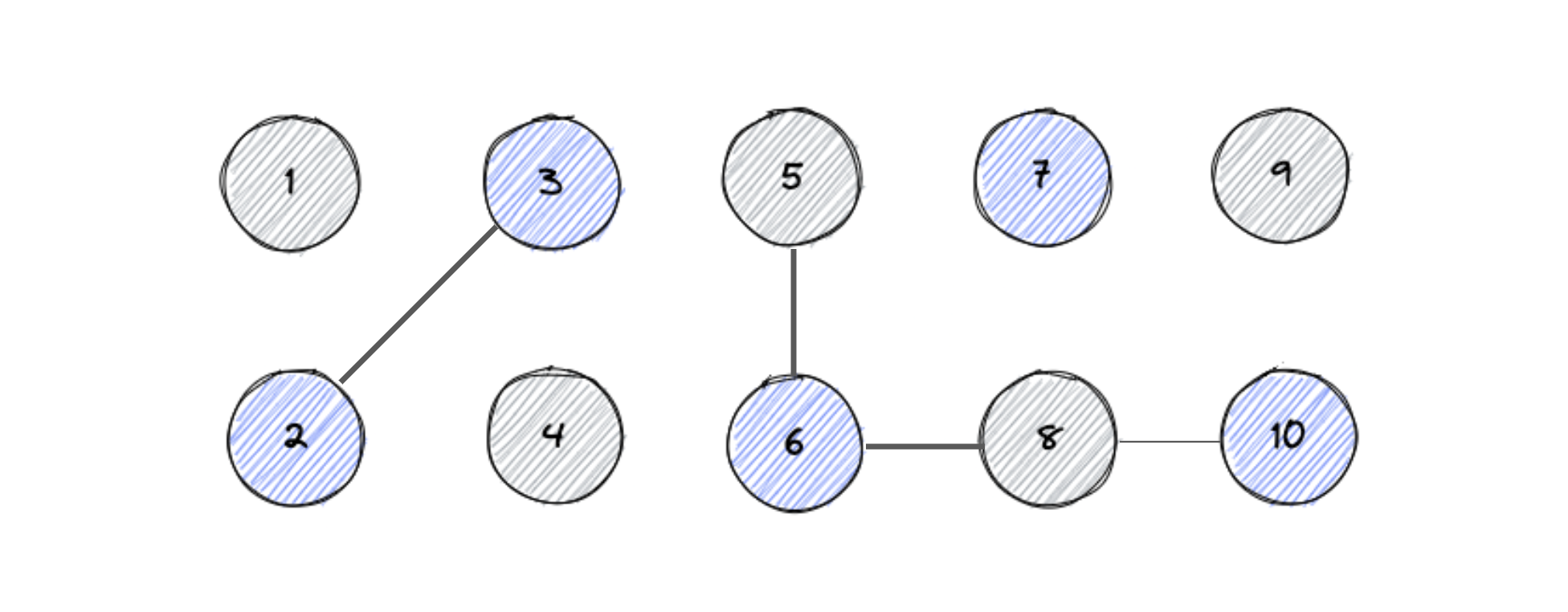
After few union commands union(2, 3), union(6, 5), union(8, 6), union(10, 8) the state of
the system changes to
We can query the above system to find if two objects are connected or not like find(0, 1) == False,
find(1, 2) == True, find(4, 9) == True, find(8, 1) == False
To be formal, we can say that “connected to” has the following properties:
Reflexive: a is connected to a.
Symmetric: if a is connected to b, then b is conntected to a.
Transitive: if a is connected to b and b is conntected to c, then a is connected to c.
Another common terminology in dynamic connectivity problems is Connected components. It refers
to the maximal set of objects that are mutually connected.
In the above example, the conntected components are {0}, {1, 2}, {3}, {4, 5, 7, 9}, {6}, {8}.
The union-find algorithms we are going to implement below can help us model objects of many different
kinds. Some of the practical examples include:
Pixels in an image.
Computers in a network.
Friends in a network.
Grid system for path finding problems.
When we are programming the union-find operations, it’s convenient to represent the set of objects
and their connectivity using a list from 0 to N-1. The overall goal is to design a data structure
and algorithm for union-find that is effecient when:
Number of ojects N can be huge.
Number of operations M can be huge.
Find and Union queries can be intermixed.
Quick-Find
We will used id[] to store all the obecjts. The index will refer to the objects and the value will
indicate the connectivity between two indices.
For example id[] = [0, 1, 1, 3, 5, 5, 6, 5, 8, 5]. Here, objects {1, 2} are connected and
{4, 5, 7, 9} are connected.
Find: Check if indices a and b have the same id.
Union: To merge indices a and b, change all entries whose id equals id[a] to id[b].
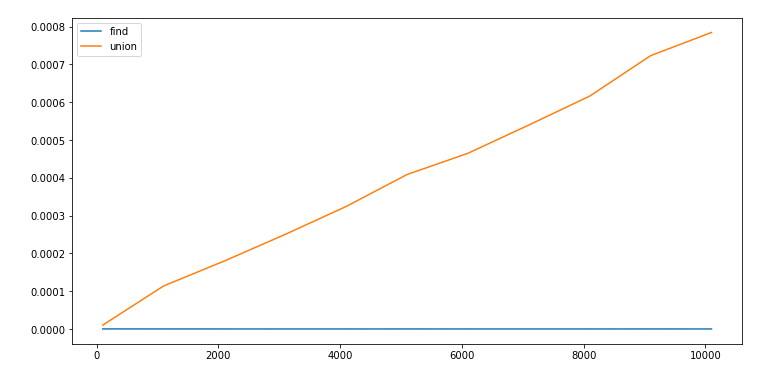
It’s easy to observe the worst case time complexity of QuickFind:
Initialize: O(N)
Union: O(N)
Find: O(1)
Even though the operations don’t look too bad on their own, for a sequence of N union commands on N
objects(a very common operation for such problems), this becomes O(N^2).
An improvement over QuickFind is the QuickUnion algorithm.
Quick-Union
Here also we use an array to store the objects, though the interpretation of the values in the array
changes, nowid[i] is the parent of i. We are essentially using the array to create a tree like
structure. To find the root of any object i, we recursively traverse it’s parent till the index is
same as the value, i.e. Root of i is id[id[id[…id[i]…]]].
Here we can observe that the Union and Find operations have a time complexity of O(logN) on
average, given that the tree remains balanced. The problem occurs when the tree gets too tall. In
the worst case, we can end up with one very tall skinny tree where the time complexity of Find
operation becomes O(N). In this case, we again end up with O(N^2) for N finds on N objects.
The QuickUnion can easily be improved by trying to keep the trees balanced as the number of operations grow.
This can be done by keeping track of the size of the trees and using it for each union(a, b)
operation. Now, instead of just changing the root of a to root of b, we compare the size of tree
at a and the tree at b to decide whose root changes.
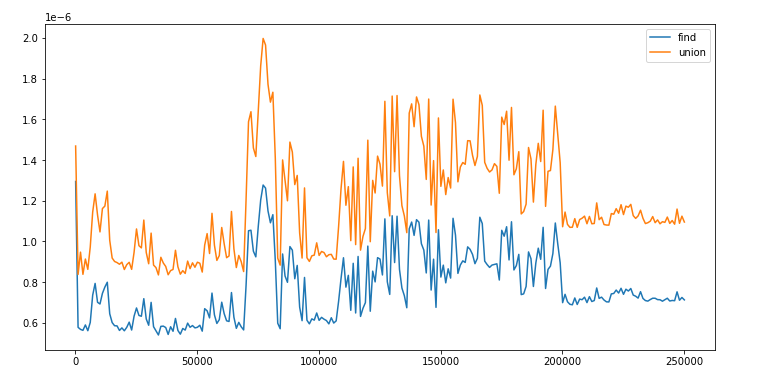
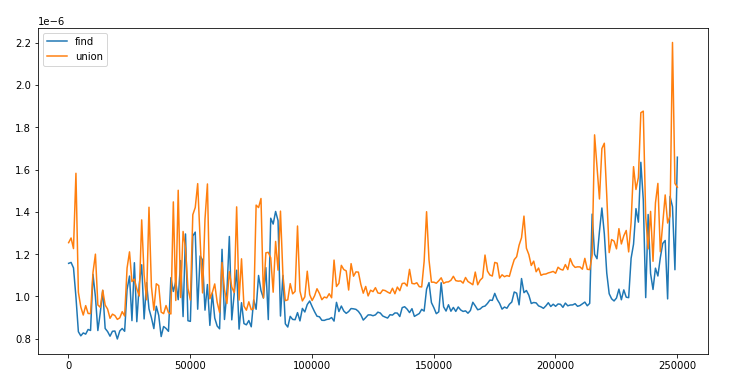
Percolation is a model for many physical systems. The system can be represented in the following way:
N-by-N grid of sites.
Each site is open with probability p (or blocked with probability 1-p).
System percolates if the top and bottom are connected by open sites.
One example can be water flowing through a block of bricks with open sites indicating porus material.
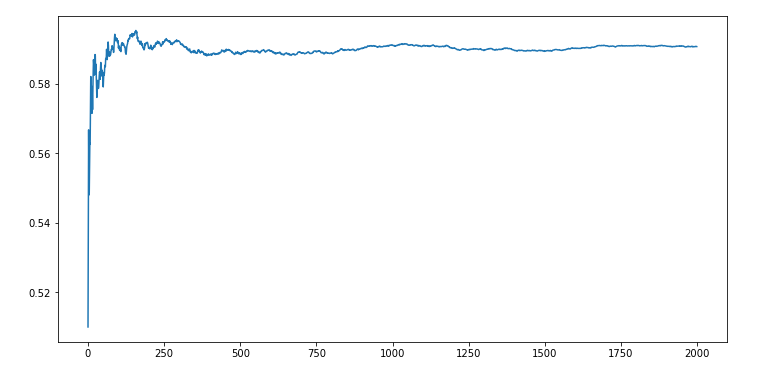
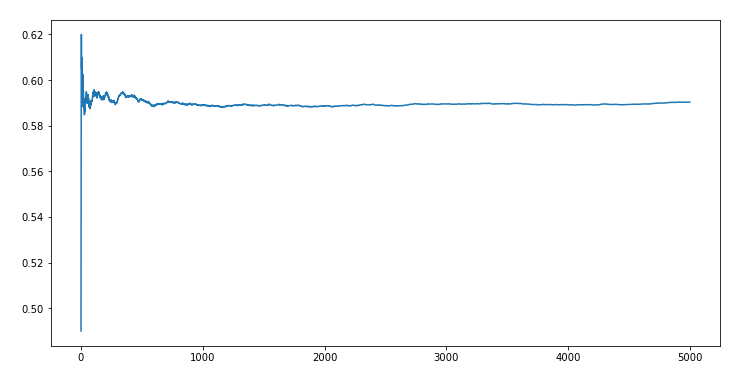
The likelihood of percolation depends on the site vacancy probability p. We will use the
QuickUnionWeighted algorithm to find the threshold for p where the liklehood of percolation changes
suddenly from 0 to 1.
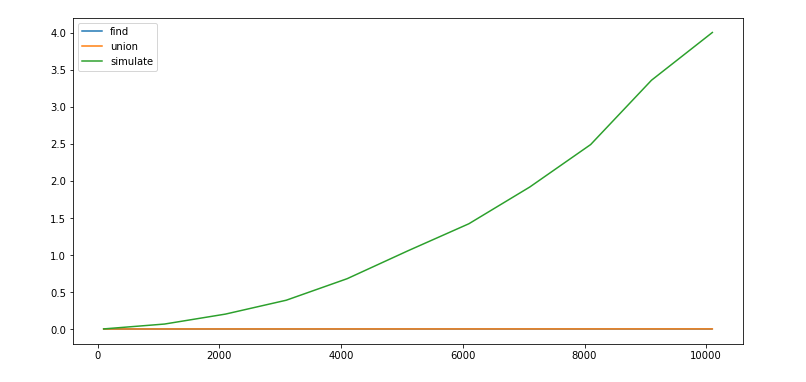
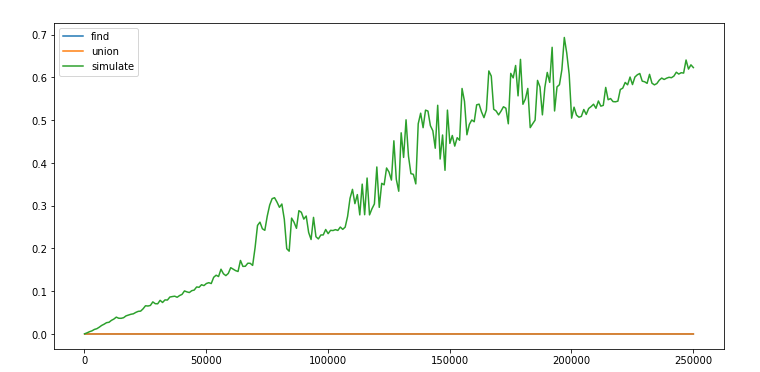
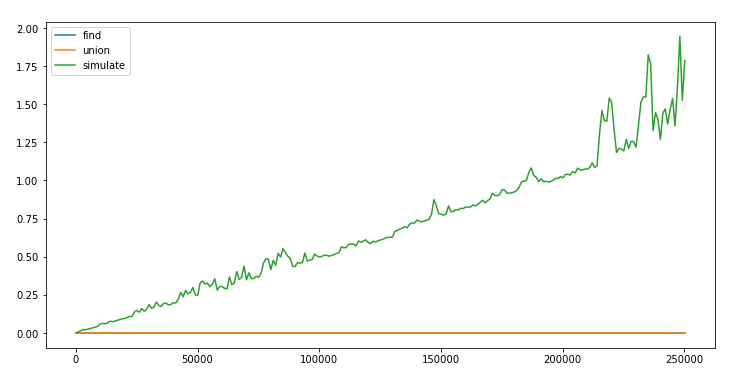
We will run monte carlo simulation on a system:
Which starts with all sites blocked.
In each step, we randomly open a site and check if the system percolates.
We keep repeating the last step till the system percolates.
We estimate p as (# open sites) / (N * N).
Repeat the above steps M(1000x) times.
If there is such a threshold for p where “the liklehood of percolation changes suddenly from 0 to
1”, then a running mean of all the p over multiple simulations should give us that number according
to the law of large numbers.