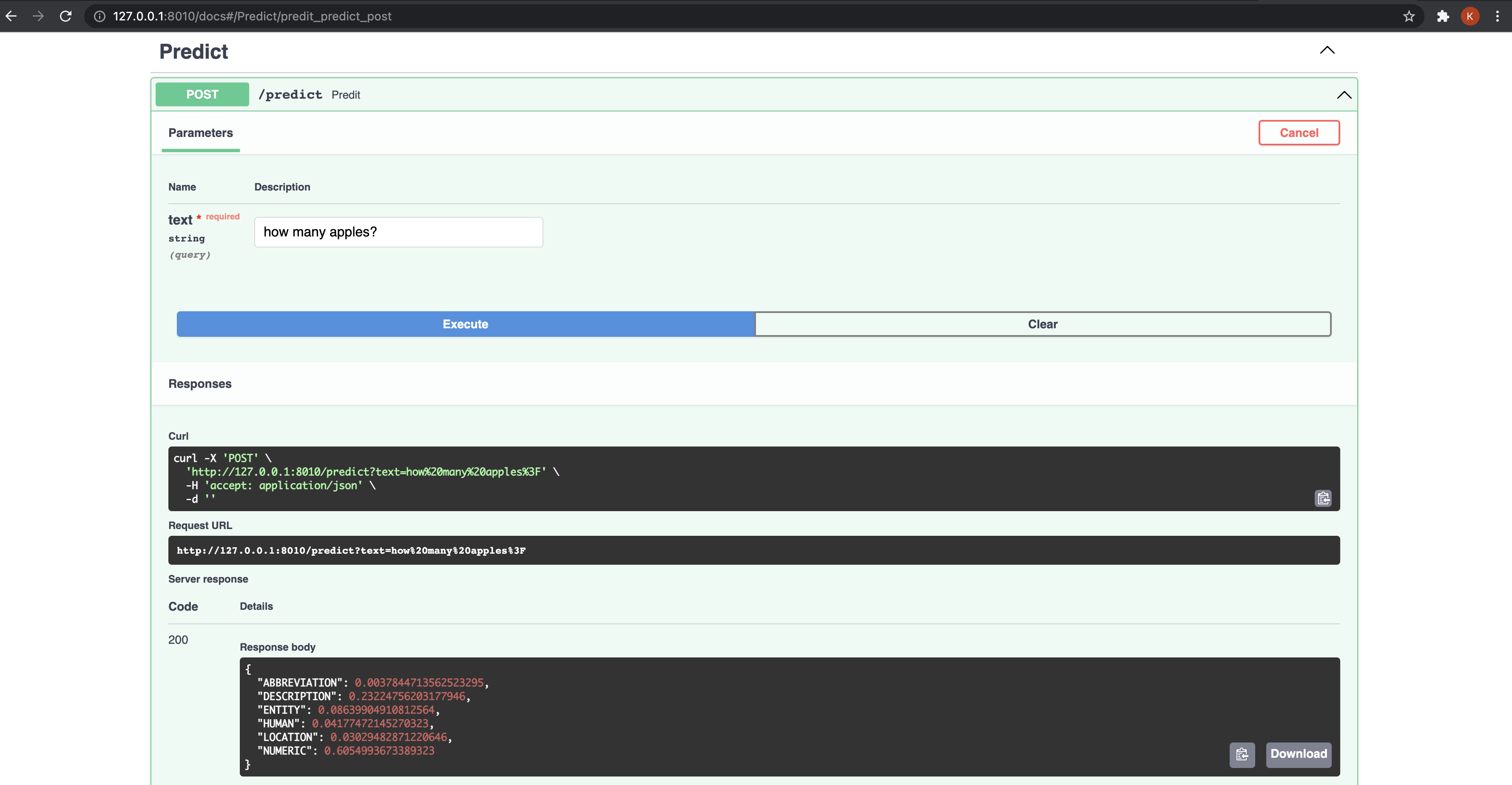
In this series of posts, we will take a small dataset and go through various steps like building Data pipelines, ML workflow management, API development and Monitoring.
These steps are necessary for operationalization of any machine-learning based
model.
These posts are in no way exhaustive in covering the breadth of MLOps. Several key pieces like the CI/CD pipeline, monitoring for drift, etc are missing at the moment, which might get added later.
Stack
We will be using the following tools in this project
$ poetry install
# Installing dependencies from lock file# No dependencies to install or update# Installing the current project: mlops (0.1.0)
MLflow
1
2
3
4
5
6
7
8
9
10
$ poetry shell
$ exportMLFLOW_S3_ENDPOINT_URL=http://127.0.0.1:9000
$ exportAWS_ACCESS_KEY_ID=minioadmin
$ exportAWS_SECRET_ACCESS_KEY=minioadmin
# make sure that the backend store and artifact locations are same in the .env file as well
$ mlflow server \
--backend-store-uri sqlite:///mlflow.db \
--default-artifact-root s3://mlflow \
--host 0.0.0.0