In this notebook, we will finetune a Cross-Encoder on Semantic Textual Similarity text.
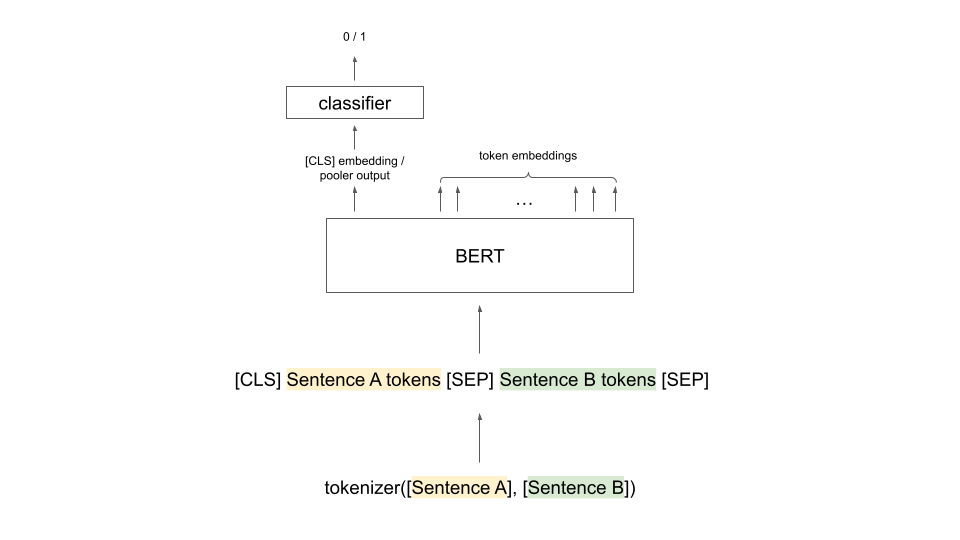
First let’s look at the architecture of a cross encoder.
In a Bi-Encoder, we pass both the sentences(A and B) separately to the finetuned model and use the pooled embeddings to compare the similarity between the sentences (cosine or dot product).
In a Cross-Encoder, we pass both the sentences together in the model and finetune the model with a linear head with output size 1, paired with a Binary Cross Entropy loss.
In case of BERT, this would look something like this -
Fig. 1. Illustration of a Cross-Encoder architecture.
Cross-Encoders perform better than Bi-Encoders, results are detailed in the original Sentence-BERT paper. However, they are not practical for most of the applications as we can’t use them to pre-compute and index our context/document embeddings.
Cross-Encoders can be used whenever you have a pre-defined set of sentence pairs you want to score. For example, you have 100 sentence pairs and you want to get similarity scores for these 100 pairs.
Bi-Encoders are used whenever you need a sentence embedding in a vector space for efficient comparison. Applications are for example Information Retrieval / Semantic Search or Clustering. Cross-Encoders would be the wrong choice for these application: Clustering 10,000 sentence with CrossEncoders would require computing similarity scores for about 50 Million sentence combinations, which takes about 65 hours. With a Bi-Encoder, you compute the embedding for each sentence, which takes only 5 seconds. You can then perform the clustering.
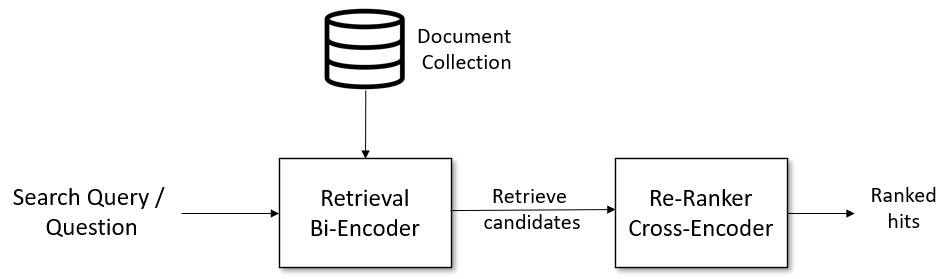
Cross-Encoders are trypically used as a Re-Ranker.
Fig. 2. Illustration of a Cross-Encoder as a Re-Ranker. (Image source: https://www.sbert.net/examples/applications/retrieve_rerank/README.html)
This is the most common setup for semantic search. We pass our Document collection though a Bi-Encoder finetuned for STS tasks and index the embeddings in a vector database.
During query time, we embed the query using the same Bi-Encoder and fetch top k candidates from our database. This is the Retrieval part.
Next, we can further refine the results by passing the top k(query, retrieved) document pairs through a Cross-Encoder finetuned for STS tasks. Cross-Encoder essentially re-sorts the retrieved candidate documents such that the top most relevant document has the highest score.
# example of next sentence prediction objective used for a cross encodertokenized_texts=tokenizer(["I am hungry."],["Order some food for me"],padding=True,truncation=True)tokenizer.decode(tokenized_texts["input_ids"][0])
'[CLS] i am hungry. [SEP] order some food for me [SEP]'
CPU times: user 246 ms, sys: 5.14 ms, total: 251 ms
Wall time: 235 ms
1
2
3
4
5
6
7
8
9
10
train_ratio=0.8n_total=len(sts_dataset)n_train=int(n_total*train_ratio)n_val=n_total-n_traintrain_dataset,val_dataset=random_split(sts_dataset,[n_train,n_val])batch_size=16# mentioned in the papertrain_dataloader=DataLoader(train_dataset,batch_size=batch_size,shuffle=True)val_dataloader=DataLoader(val_dataset,batch_size=batch_size,shuffle=False)
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertModel: ['cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.predictions.bias']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
1
2
3
4
5
6
7
8
# optimizer, lr, num_warmup steps have been picked from the paperoptimizer=torch.optim.Adam(model.parameters(),lr=3e-5)total_steps=len(train_dataset)//batch_sizewarmup_steps=int(0.1*total_steps)scheduler=get_linear_schedule_with_warmup(optimizer,num_warmup_steps=warmup_steps,num_training_steps=total_steps-warmup_steps)loss_fn=torch.nn.BCEWithLogitsLoss()
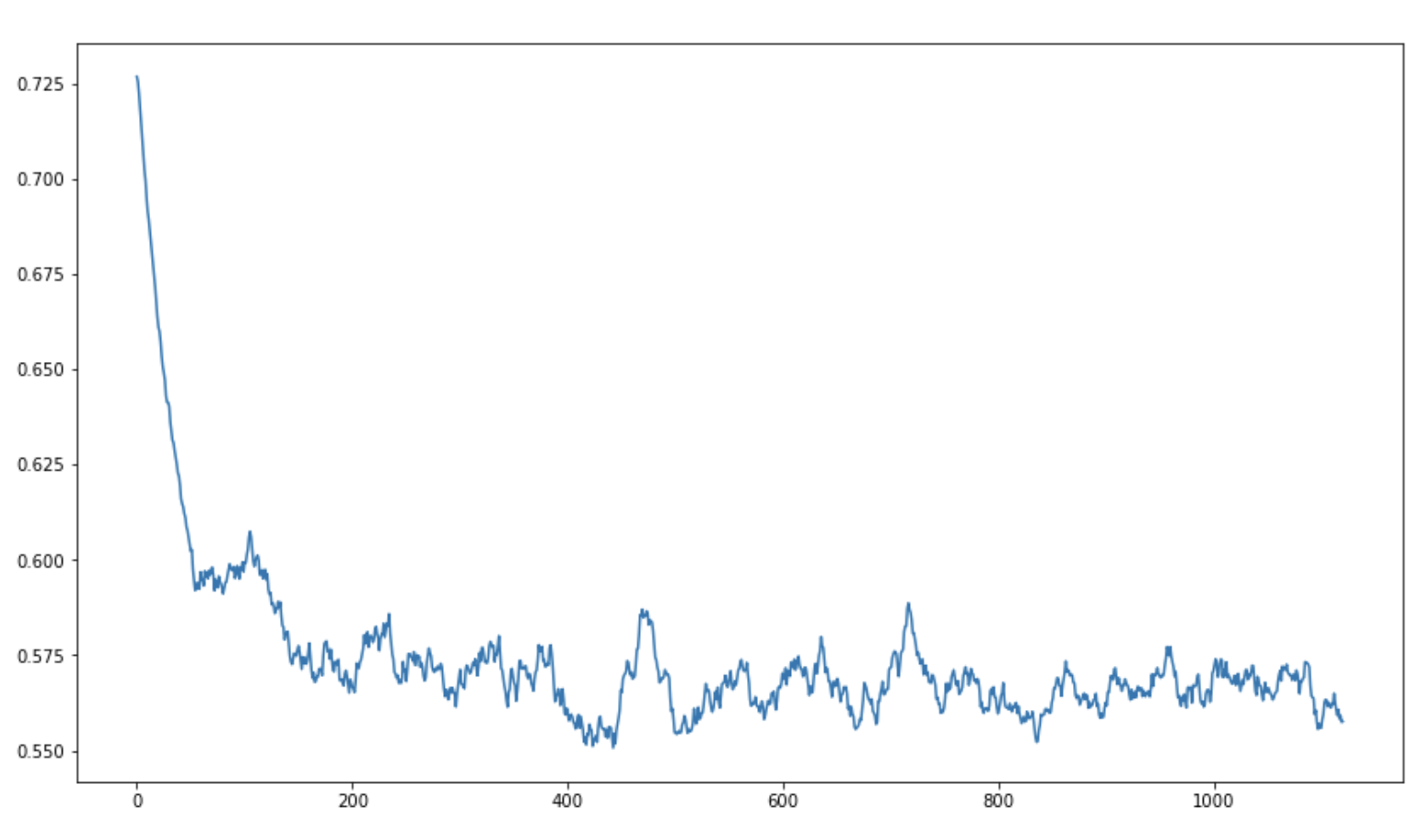
** Validation loss staying the same indicates that something is off. Please let me know if someone finds the issue.
Normally we look at losses over multiple epochs, but here we have only 4 epochs. One way to look at the mini batch losses is to use a running mean(smoothing) to reduce noise from per batch loss.
Let’s look at how this finetuned Cross-Encoder can be used to rank a collection of documents for a query.
We will look at few examples to manually inspect our finetuned model and the base-bert model.
corpus=["A man is eating food.","A man is eating a piece of bread.","The girl is carrying a baby.","A man is riding a horse.","A woman is playing violin.","Two men pushed carts through the woods.","A man is riding a white horse on an enclosed ground.","A monkey is playing drums.","A cheetah is running behind its prey."]query="A man is eating pasta."
Query - A man is eating pasta. [Finetuned Cross-Encoder]
---
0.74 A man is eating food.
0.41 A man is eating a piece of bread.
0.15 The girl is carrying a baby.
0.14 Two men pushed carts through the woods.
0.13 A man is riding a horse.
0.12 A woman is playing violin.
0.12 A man is riding a white horse on an enclosed ground.
0.12 A monkey is playing drums.
0.11 A cheetah is running behind its prey.
Query - A man is eating pasta. [Bert Base]
---
0.51 Two men pushed carts through the woods.
0.37 A man is eating food.
0.37 A man is eating a piece of bread.
0.37 A man is riding a horse.
0.36 A woman is playing violin.
0.36 A man is riding a white horse on an enclosed ground.
0.36 The girl is carrying a baby.
0.36 A monkey is playing drums.
0.36 A cheetah is running behind its prey.
1
2
3
4
5
6
7
8
9
10
corpus=["A man is eating food.","A man is eating a piece of bread.","A woman is playing violin.","Two men pushed carts through the woods.","A woman is practicing jumps with her horse.","A horse is running around the track."]query="Horse jumped over the obstacle."
Query - Horse jumped over the obstacle. [Finetuned Cross-Encoder]
---
0.62 A woman is practicing jumps with her horse.
0.57 A horse is running around the track.
0.27 A woman is playing violin.
0.19 Two men pushed carts through the woods.
0.18 A man is eating a piece of bread.
0.14 A man is eating food.
Query - Horse jumped over the obstacle. [Bert Base]
---
0.54 A man is eating a piece of bread.
0.54 A woman is playing violin.
0.48 A man is eating food.
0.37 Two men pushed carts through the woods.
0.36 A woman is practicing jumps with her horse.
0.36 A horse is running around the track.
In both the examples we can see that our model is able to find the most relevant document from the corpus. Also, our finetuned model is pushing down the scores for non-relevant documents in the corpus, the bert-base model is scoring pretty much every document above .35 in this example.