In this notebook we will finetune the bert-base model for semantic search using Multiple Negative Ranking loss.
This will be mostly similar to the finetuning we did in the previous notebook. The main changes are:
We won’t use a fully connected layer on top of the embeddings now
We will use Multiple Negative Ranking loss
We will compute cosine similarity between the pooled u and v embedding and use that in MNR
MNR loss
This loss expects as input a batch consisting of sentence pairs (a_1, p_1), (a_2, p_2)…, (a_n, p_n) where we assume that (a_i, p_i) are a positive pair and (a_i, p_j) for i!=j a negative pair.
For each a_i, it uses all other p_j as negative samples, i.e., for a_i, we have 1 positive example (p_i) and n-1 negative examples (p_j). It then minimizes the negative log-likelihood for softmax normalized scores. This loss function works great to train embeddings for retrieval setups where you have positive pairs (e.g. (query, relevant_doc)) as it will sample in each batch n-1 negative docs randomly.
The performance usually increases with increasing batch sizes.
Reusing dataset snli (/home/utsav/.cache/huggingface/datasets/snli/plain_text/1.0.0/1f60b67533b65ae0275561ff7828aad5ee4282d0e6f844fd148d05d3c6ea251b)
Loading cached processed dataset at /home/utsav/.cache/huggingface/datasets/snli/plain_text/1.0.0/1f60b67533b65ae0275561ff7828aad5ee4282d0e6f844fd148d05d3c6ea251b/cache-737deef8acadbdc5.arrow
(183416,
{'premise': 'A person on a horse jumps over a broken down airplane.',
'hypothesis': 'A person is outdoors, on a horse.',
'label': 0})
Let’s look at an example of MNR loss using (anchor, positive) pairs per batch, based on the description provided by the sentence_transformers library.
['A person on a horse jumps over a broken down airplane.',
'Children smiling and waving at camera',
'A boy is jumping on skateboard in the middle of a red bridge.',
'Two blond women are hugging one another.',
'A few people in a restaurant setting, one of them is drinking orange juice.',
'An older man is drinking orange juice at a restaurant.',
'A man with blond-hair, and a brown shirt drinking out of a public water fountain.',
'Two women who just had lunch hugging and saying goodbye.']
1
positives
['A person is outdoors, on a horse.',
'There are children present',
'The boy does a skateboarding trick.',
'There are women showing affection.',
'The diners are at a restaurant.',
'A man is drinking juice.',
'A blond man drinking water from a fountain.',
'There are two woman in this picture.']
Here we will use a fintuned model to try and show an example with good representations for the sentences instead of using random gibberish values.
Here, each row in the similarity_matrix can be thought of as unnormalized scores for a class and each entry in the target array corresponds to the corresponding class label for that similarity row. The diagonal entries are our (anchor, positive) pairs hence they have the highest scores(this won’t be the case with a bert-base model which hasn’t been finetuned for STS, we observe this behavior here since we are using a model finetuned on STS tasks).
CPU times: user 4.11 s, sys: 242 ms, total: 4.36 s
Wall time: 4.35 s
1
2
3
4
5
6
7
8
9
10
train_ratio=0.8n_total=len(snli_dataset)n_train=int(n_total*train_ratio)n_val=n_total-n_traintrain_dataset,val_dataset=random_split(snli_dataset,[n_train,n_val])batch_size=16# mentioned in the papertrain_dataloader=DataLoader(train_dataset,batch_size=batch_size,shuffle=True)val_dataloader=DataLoader(val_dataset,batch_size=batch_size,shuffle=False)
The method mean_pool() implements the mean token pooling strategy mentioned in the paper. The implementation has been picked up from the sentence_transformers library.
We will use the encode() method to compute pooled embeddings using the finetuned and the bert-base models later to evaluate the results on STS tasks.
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertModel: ['cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.weight', 'cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.bias']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
1
2
3
4
5
6
7
8
# optimizer, lr, num_warmup steps have been picked from the paperoptimizer=torch.optim.Adam(model.parameters(),lr=2e-5)total_steps=len(train_dataset)//batch_sizewarmup_steps=int(0.1*total_steps)scheduler=get_linear_schedule_with_warmup(optimizer,num_warmup_steps=warmup_steps,num_training_steps=total_steps-warmup_steps)loss_fn=torch.nn.CrossEntropyLoss()
1
model=model.to(device)
Training loop
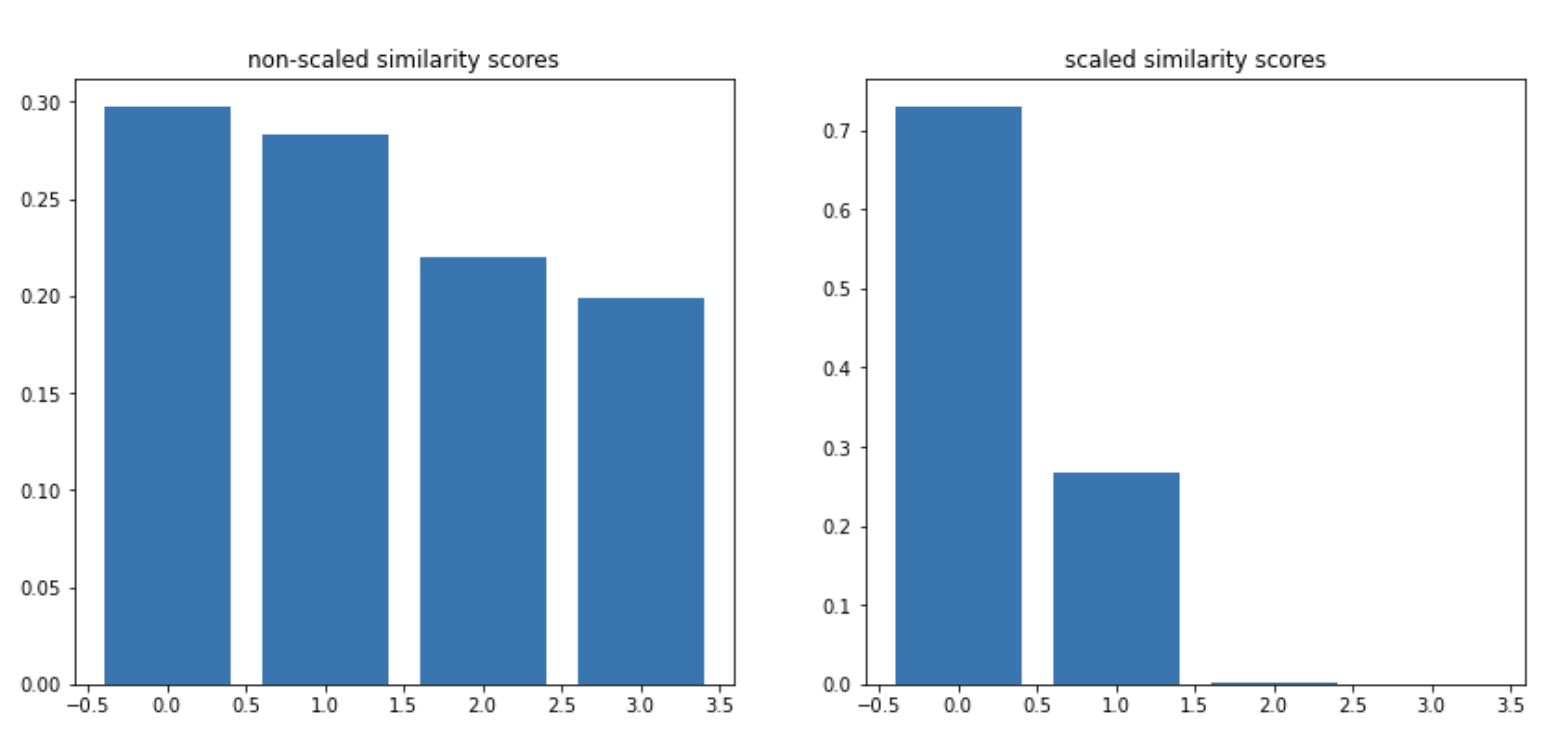
While calculating the loss per batch, using the similarity matrix(from anchors and positives) and the target tensor, we scale the similarity matrix by a constant first. We are using a scaling factor of 20 as used in the sentence_transformer library.
The reason for this scaling(from what i can tell) is the same as using temperature while decoding from seq2seq models. Essentially we want to make the distribution of scores(similarity in this case) more peaky(this amounts to lowering the temperature while decoding).
For example, consider a batch size 4 with similarity scores [0.8, 0.75, 0.5, 0.4] with similarity(anchor, positive) = 0.8.
defget_train_step_fn(model:torch.nn.Module,optimizer:torch.optim.Optimizer,scheduler:torch.optim.lr_scheduler.LambdaLR,loss_fn:torch.nn.CrossEntropyLoss)->Callable[[torch.tensor],float]:deftrain_step_fn(x:torch.tensor)->float:model.train()anchor_encodings,positive_encodings=model(x)similarity_matrix=util.cos_sim(anchor_encodings,positive_encodings)target=torch.tensor(range(len(anchor_encodings)),dtype=torch.long,device=device)loss=loss_fn(similarity_matrix*20,target)loss.backward()optimizer.step()scheduler.step()optimizer.zero_grad()returnloss.item()returntrain_step_fndefget_val_step_fn(model:torch.nn.Module,loss_fn:torch.nn.CrossEntropyLoss)->Callable[[torch.tensor],float]:defval_step_fn(x:torch.tensor)->float:model.eval()anchor_encodings,postiive_encodings=model(x)similarity_matrix=util.cos_sim(anchor_encodings,postiive_encodings)target=torch.tensor(range(len(anchor_encodings)),dtype=torch.long,device=device)loss=loss_fn(similarity_matrix*20,target)returnloss.item()returnval_step_fndefmini_batch(dataloader:DataLoader,step_fn:Callable[[torch.tensor],float],is_training:bool=True)->tuple[np.array,list[float]]:mini_batch_losses=[]ifis_training:print("\nTraining ...")else:print("\nValidating ...")n_steps=len(dataloader)fori,datainenumerate(dataloader):loss=step_fn(data)mini_batch_losses.append(loss)ifi%(batch_size*100)==0:print(f"step {i:>5}/{n_steps}, loss = {loss: .3f}")returnnp.mean(mini_batch_losses),mini_batch_losses
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
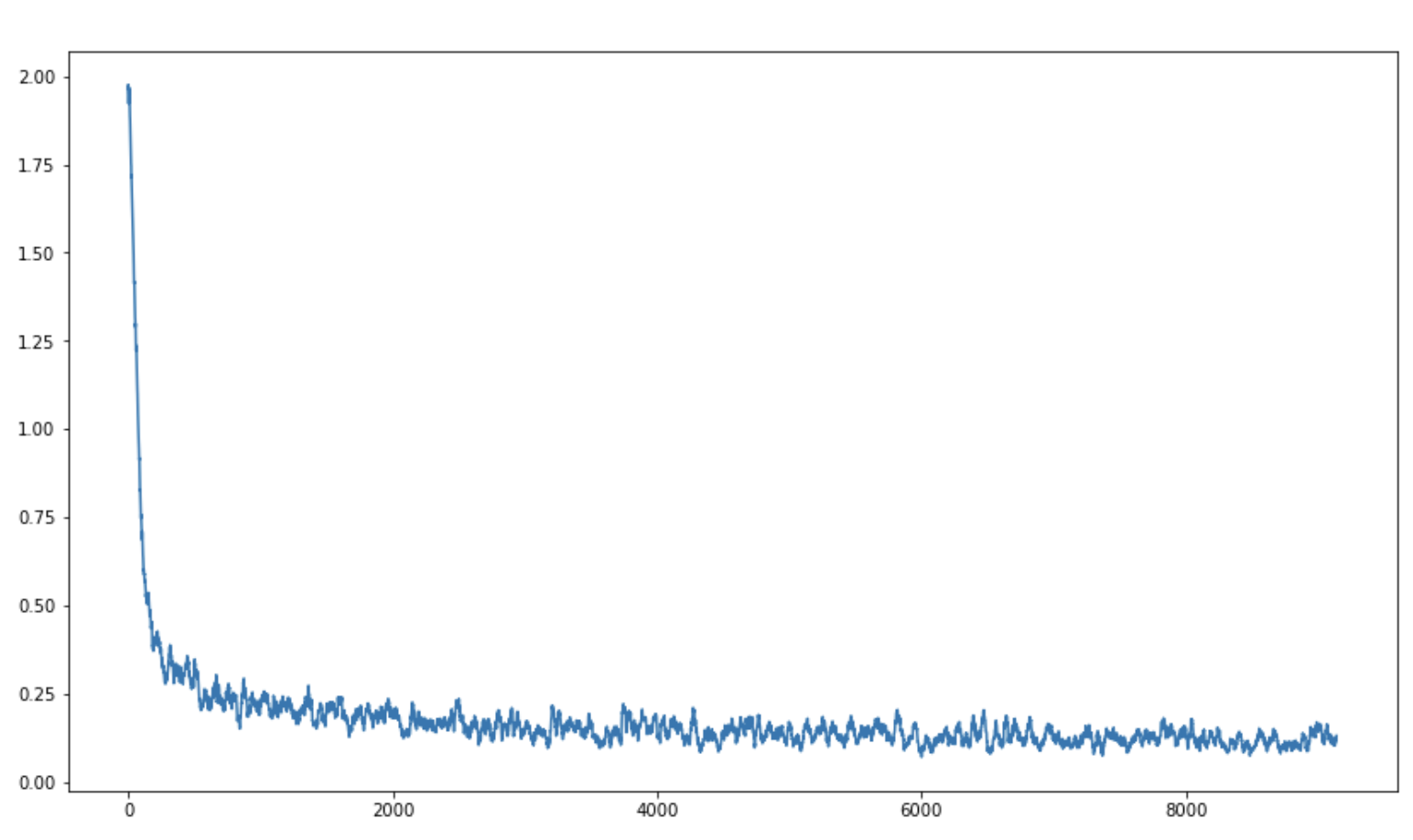
%%timen_epochs=1# mentioned in the papertrain_step_fn=get_train_step_fn(model,optimizer,scheduler,loss_fn)val_step_fn=get_val_step_fn(model,loss_fn)train_losses,train_mini_batch_losses=[],[]val_losses,val_mini_batch_losses=[],[]forepochinrange(1,n_epochs+1):train_loss,_train_mini_batch_losses=mini_batch(train_dataloader,train_step_fn)train_mini_batch_losses+=_train_mini_batch_lossestrain_losses.append(train_loss)withtorch.no_grad():val_loss,_val_mini_batch_losses=mini_batch(val_dataloader,val_step_fn,is_training=False)val_mini_batch_losses+=_val_mini_batch_lossesval_losses.append(val_loss)
Training ...
step 0/9171, loss = 1.716
step 1600/9171, loss = 0.286
step 3200/9171, loss = 0.055
step 4800/9171, loss = 0.172
step 6400/9171, loss = 0.037
step 8000/9171, loss = 0.266
Validating ...
step 0/2293, loss = 0.122
step 1600/2293, loss = 0.043
CPU times: user 20min 46s, sys: 6min 21s, total: 27min 7s
Wall time: 27min 3s
1
train_loss,val_loss
(0.176284230241434, 0.1142814209404556)
Normally we look at losses over multiple epochs, but here we have only 1 epoch. One way to look at the mini batch losses is to use a running mean(smoothing) to reduce noise from per batch loss.
Here we will manually inspect the performance of our finetuned model as well as use a STS dataset for evaluation on a similar task as mentioned in the paper.
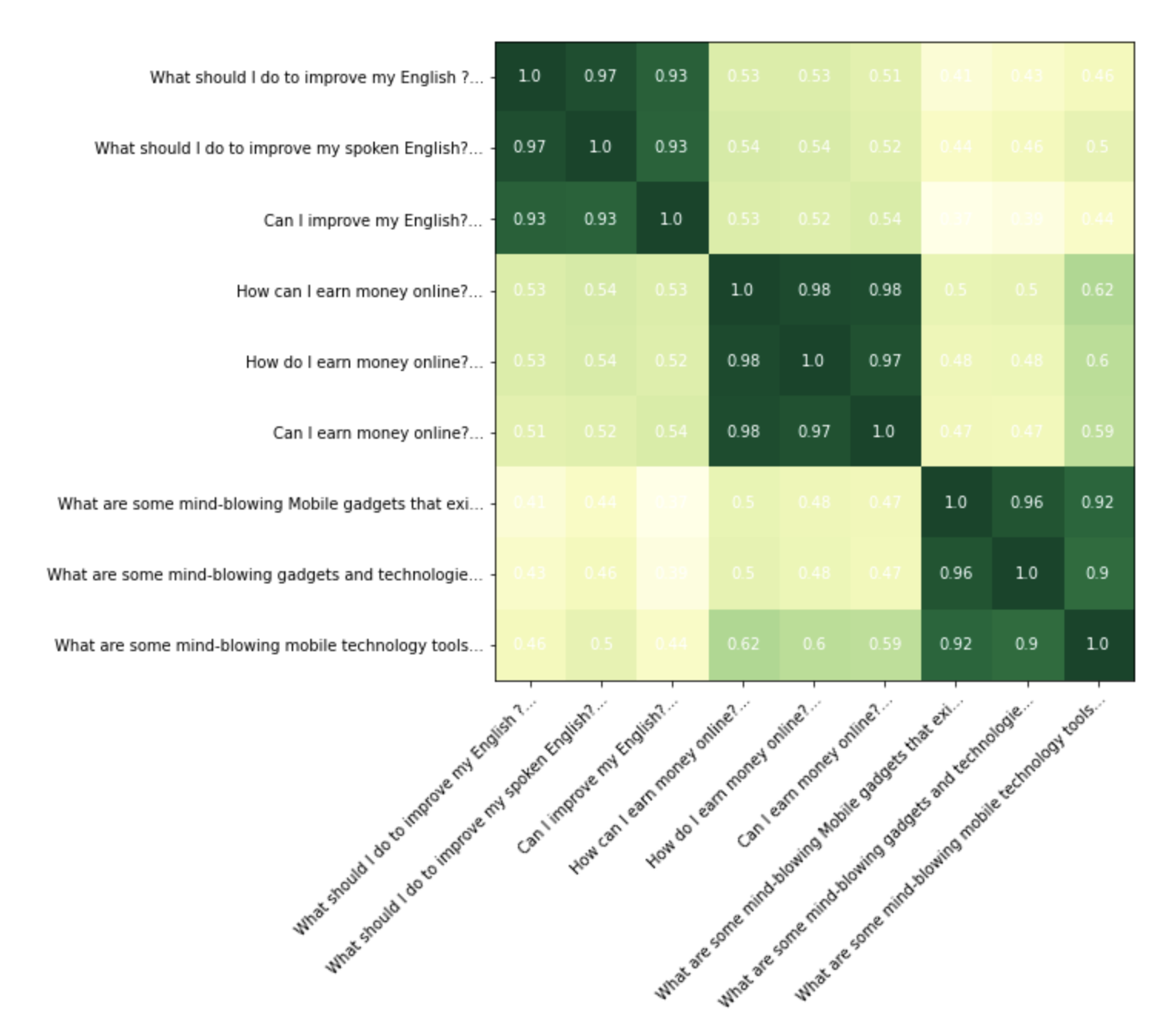
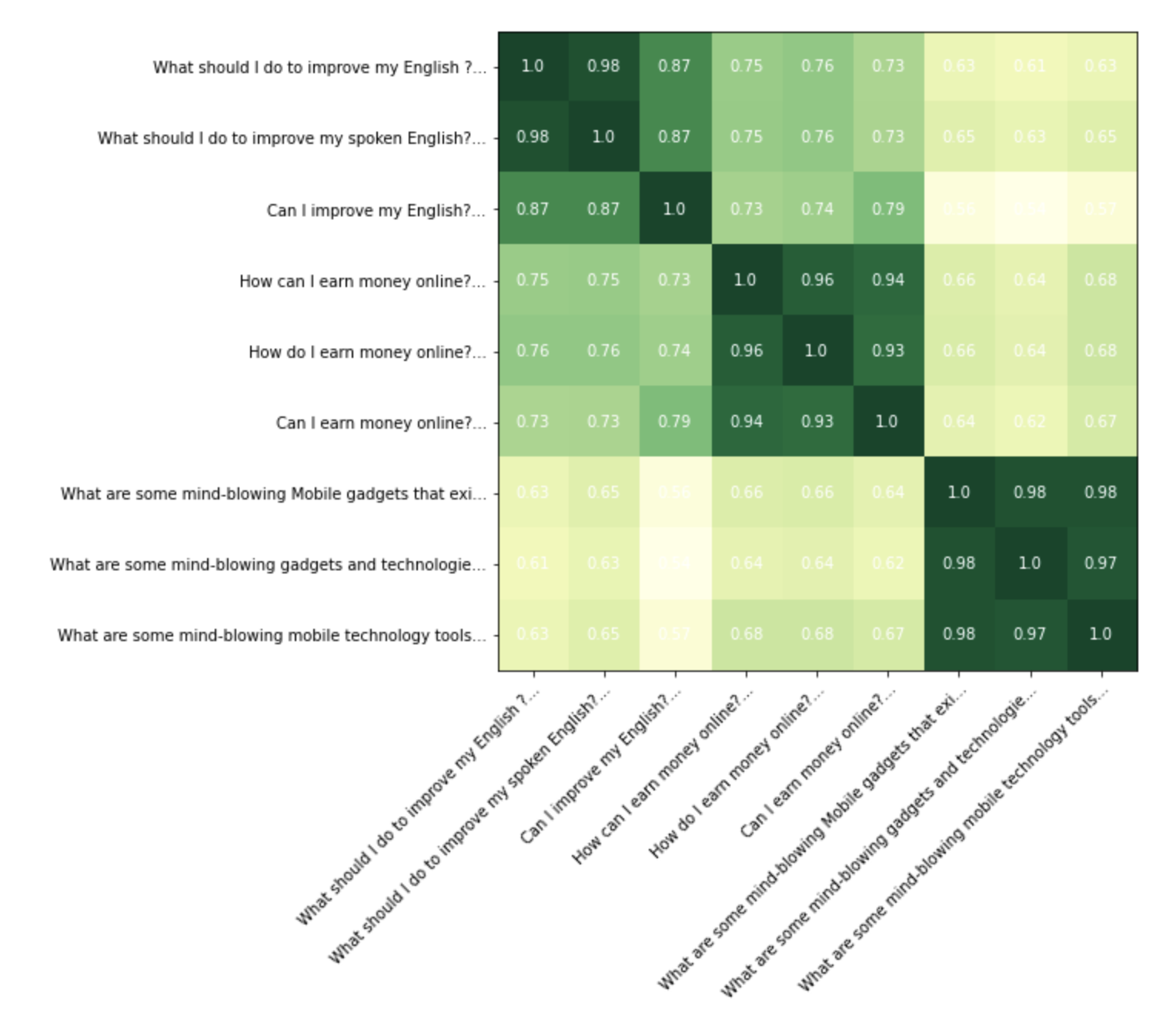
For manual inspection, we have taken few texts which fall neatly into three clusters. We want to see how neatly our finetuned model(and the bert-base model) is able to find these clusters.
sentences=["What should I do to improve my English ?","What should I do to improve my spoken English?","Can I improve my English?","How can I earn money online?","How do I earn money online?","Can I earn money online?","What are some mind-blowing Mobile gadgets that exist that most people don't know about?","What are some mind-blowing gadgets and technologies that exist that most people don't know about?","What are some mind-blowing mobile technology tools that exist that most people don't know about?"]
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertModel: ['cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
On a visual inspection we can see that our finetuned model is doing a better job in encoding the texts so that the clusters are clearly visible. Specifically it’s doing a better job in pushing down the scores for non similar text pairs.
Reusing dataset glue (/home/utsav/.cache/huggingface/datasets/glue/stsb/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
(1500,
{'sentence1': 'A man with a hard hat is dancing.',
'sentence2': 'A man wearing a hard hat is dancing.',
'label': 5.0,
'idx': 0})
Our finetuned model using MNR loss is doing even better than the model we finetuned in the previous notebook using the classification objective, with lesser training data and steps as well.