We will briefly talk about sparse and dense representations of texts and take a quick glance at techniques that came before the Transformers.
Sparse representation of text: One-hot vectors
Traditionally we use a one-hot vectors to represent text as vectors. For example, for a sentence “a quick brown fox”, we could end up with following one hot vectors.
[1, 0, 0, 0] - a
[0, 1, 0, 0] - quick
[0, 0, 1, 1] - brown
[0, 0, 0, 1] - fox
It’s easy to see that for larger vocabularies such as web pages, faq articles, etc. i.e. the kind we typically see in IR settings, these vectors will be very long and very sparse with the dimensionality equal to the vocab size.
These vectors also have no information about the words they represent. For example, here “quick” is as similar to “fox” as it is to the word “brown”.
** Vocab size refers to the number of unique tokens/terms used in a collection of documents.
Distributional Semantics
Formally, dense representation of text is easy to define
$$ f(text) => !R^n $$
In the above example, if we take n = 5, our dense vectors might look like
[0.98, -1.12, 0.21, 0.01] - a
[1.22, 2.12, -3.12, 3.11] - quick
[-1.23, 4.30, 1.16, 0.90] - brown
[0.11, 0.12, -1.23, 4.65] - fox
To capture the meaning of words in such dense vectors, we need to consider the notion of context for words in a piece of text. For example, consider these texts:
1. A bottle of ________ is on the table.
2. Everyone likes ________.
3. ________ makes you drunk.
4. We make ________ out of corn.
Now consider the word that could appear in the blank position. Given the context, we can guess it’s an alcoholic beverage (the correct answer is tezguino btw).
Other alcoholic drinks made of corn also qualify here. The idea is that we can guess the word based on the it’s surrounding words or the context in which it appears.
Techniques like word2vec, LSTMs, transformers build on top of this idea.
Before Transformers
Count based methods
The general process of creating dense representations using count based methods is to:
- Create a word-context matrix.
- Reduce it’s dimensionality.
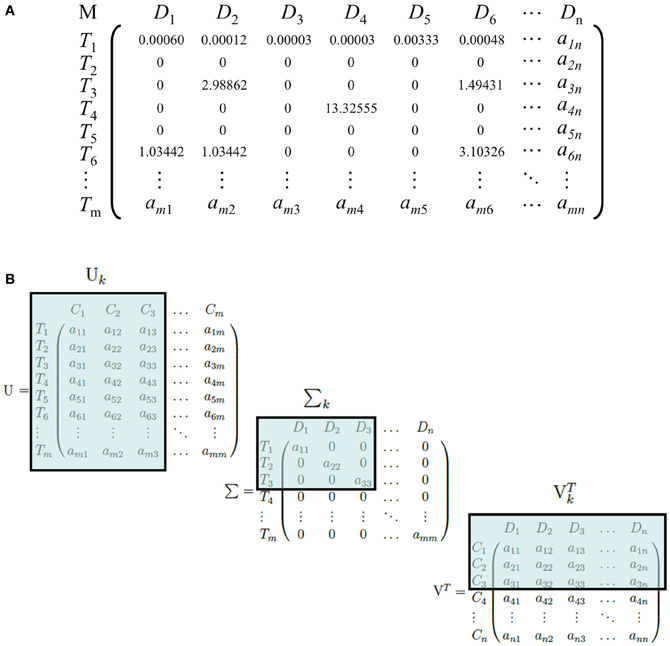
We reduce dimensionality because of the large vocab size as well as the sparsity of such matrices(most of the terms are 0 in the matrix). One such technique is LSA(Latent Semantic Analysis) which does SVD on the term document matrix(could be TF_IDF).
Word2Vec
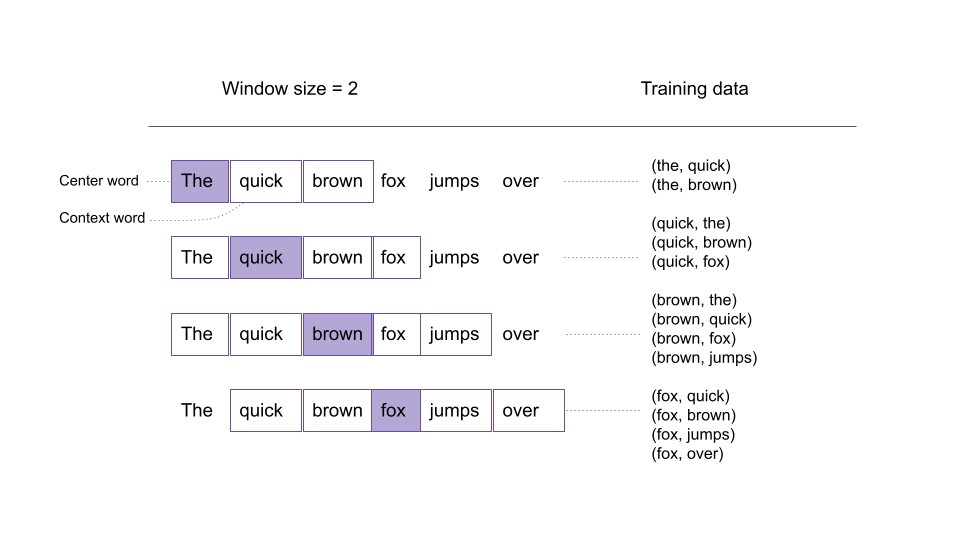
Word2Vec works on the similar premise of encoding contextual information into the dense representation for a word. Word2Vec works in an iterative manner:
- Start with a huge text corpus.
- Go over the text using a sliding window. At each step, take a center word i and the context words(within the window).
- For the center word, compute probabilities for all the words in the vocab using softmax.
- Computer cross entropy loss for the context words and backprop over the embeddings to refine them.
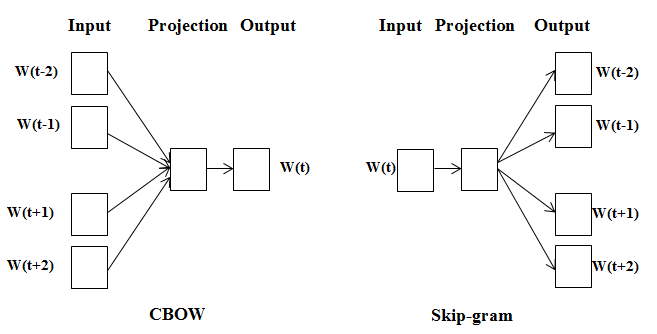
There are two methods used to create the word embeddings:
- CBOW(Continuous bag of words): Uses the context words to predict the center word.
- Skip gram: Uses the center word to predict the context words.
The objective function is formulated as
$$ J(\theta) = - \frac{1}{T} \sum_{t=1}^T \sum_{-m<=j<=m, j\neq0} P(w_{t+j}|w_t,\theta) $$
Where $P(w_{t+j}|w_t,\theta)$ is the probability of the context word given center word(skip gram).
Essentially we are going over the whole text using a sliding window and computing the loss using the probability from softmax.
Some of the drawbacks of Wor2Vec:
- Essentially a bag of words technique as we don’t consider the order in which the words appear in a window.
- Limited window size makes the learned representations very limited in the sense that they only capture very local contexts.
- We can’t capture multiple embeddings for the same word in different context, for example, “a river bank”, “bank deposit”. The word “bank” ends with a single embedding even though it means two different things here.
- Out of vocab words are not handled.
There are methods to deal with some of these issues, like subword embeddings using fastText can handle out of vocab words. In general these bag of wordd techniques have fallen out of favor for methods we are going to discuss next.
Recurrent Neural Nets
Before Transformers, RNNs especially LSTMs were all the rage but they have also fallen out of favour because of the following drawbacks:
- The temporal dependence in updating the hidden state(over the tokens) make then slow to train and not let us efficiently use the modern hardware for training(gpus).
- Even though theoretically LSTMs can handle arbitrarily long sequences, in practice they suffer from vanishing gradient.
- The biggest problem is the bottleneck at the end of the sequence where we are trying to store all the historical information from the sequence into one final hidden vector.
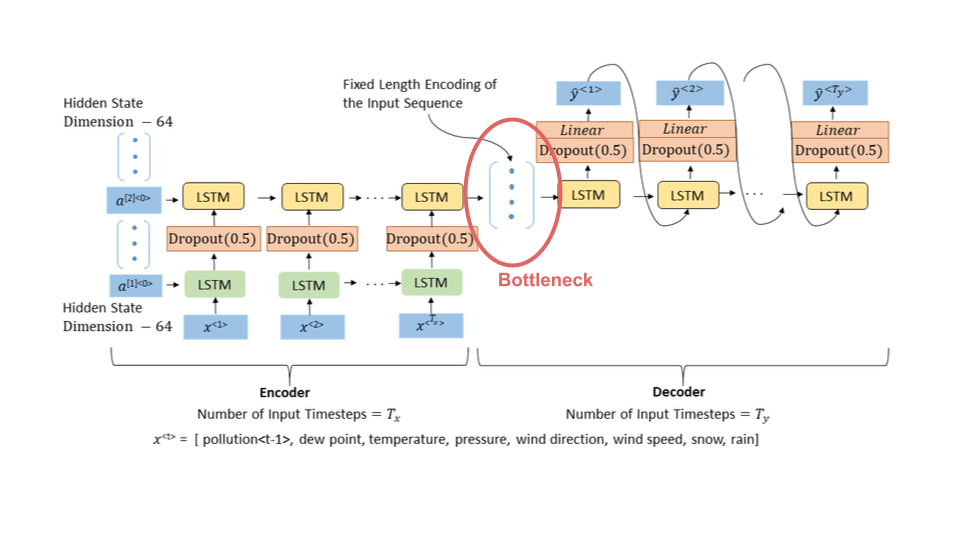
The attention mechanism on top of the LSTMs help us solve this bottleneck issue but we still struggle with slow training times as discussed in the first point.
As Transformers have proven, we don’t really need this recurrent mechanism, by adding positional information into each token embedding and doing self attention on top of it, we can learn powerful representations of text and use them for all the downstream NLP tasks.
Transformers for semantic search
** Note that we won’t go into the architectural details of transformer based models but jump straight into using these models(finetuning) for IR. There is enough content out there on this topic to justify a quick summary here.
We will cover the following techniques/architectures over multiple notebooks:
- Bi-Encoders
- Cross-Encoders
- Multilingual models
- Domain adaptation
- TSDAE(Transformer-based Sequential Denoising Auto Encoder)
- SimCSE(Simple Contrastive learning of Sentence Embeddings)
- GPL(Generative Pseudo Labeling)
- QnA(REALM)
Later we will also look into ANN(Approximate nearest neighbor) techniques used for indexing and retrieval of dense embeddings.
In rest of this notebook, we will dive into the original Sentence-BERT paper by Nils Reimers and Iryna Gurevych. Here is a quick summary by the authors.
BERT (Devlin et al., 2018) and RoBERTa (Liu et al., 2019) has set a new state-of-the-art performance on sentence-pair regression tasks like semantic textual similarity (STS). However, it requires that both sentences are fed into the network, which causes a massive computational overhead: Finding the most similar pair in a collection of 10,000 sentences requires about 50 million inference computations (~65 hours) with BERT. The construction of BERT makes it unsuitable for semantic similarity search as well as for unsupervised tasks like clustering.
In this publication, we present Sentence-BERT (SBERT), a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This reduces the effort for finding the most similar pair from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT.
We evaluate SBERT and SRoBERTa on common STS tasks and transfer learning tasks, where it outperforms other state-of-the-art sentence embeddings methods.
We will finetune the base-bert model using a siamese architecture(Bi-Encoder) on the SNLI data(the paper mentions using both the SNLI and Multi-NLI datasets).
Natural language inference(NLI) is the task of determining whether a “hypothesis” is true (entailment), false (contradiction), or undetermined (neutral) given a “premise”.
Example:
Premise Label Hypothesis A man inspects the uniform of a figure in some East Asian country. contradiction The man is sleeping. An older and younger man smiling. neutral Two men are smiling and laughing at the cats playing on the floor. A soccer game with multiple males playing. entailment Some men are playing a sport. Source: http://nlpprogress.com/english/natural_language_inference.html
** NLI is also referred as a textual entailment task.
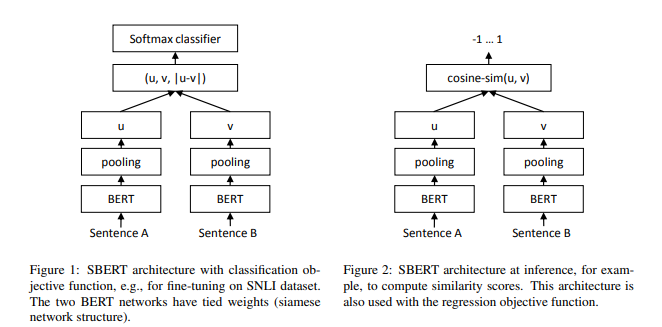
In the figure, though it looks like two different BERT models, we are finetuning only one BERT model by passing both the sentences, pooling and then feeding the embeddings into a fully connected network for classification using the cross-entropy(softmax) as the loss function.
We will train the SBERT architecture from the above figure. In the paper the authors mention three objective functions:
- Classification objective - As depicted in the picture.
- Regression objective - The cosine-similarity between the two sentence embeddings u and v is computed(Figure 2) and the model is finetuned using the mean-squared loss function.
- Triplet objective - Or MNR (Multiple Negative Ranking) loss. We will discuss this in detail in the next section. MNR in general performs better for semantic search and other use cases like clustering, paraphrase mining etc using dense embeddings.
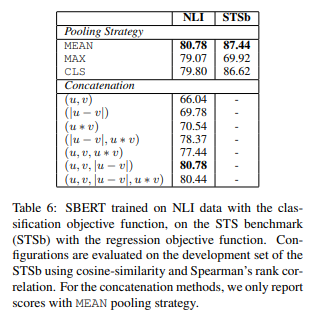
A quick note on the pooling operation, the authors mention that they tried pooling using the CLS-token, by computing the mean over all the token level embeddings (MEAN-strategy) and computing the max over the all the token level embeddings (MAX-strategy). Out of the three, MEAN pooling gave the best results hence we will try that.
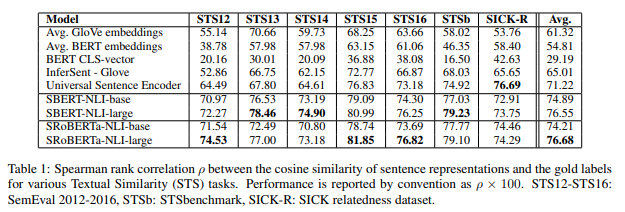
One might wonder, why the need to finetune at all, why not use the CLS-token or the MEAN pooling strategy directly with a bert model trained on MLM task. Here also, the authors share some results, unless we finetune specifically for STS(Semantic Textual Similarity) tasks, the BERT models perform worse than the Avg. GloVE embeddings on STS tasks.
They also tried various concatenation strategies before feeding the embeddings into the fully connected layer. (u, v, |u - v|) gave the best results.
Let’s start …
|
|
|
|
|
|
Data preparation
We will import the snli data and tokenize it beforehand to save compute during the training phase.
|
|
Reusing dataset snli (/home/utsav/.cache/huggingface/datasets/snli/plain_text/1.0.0/1f60b67533b65ae0275561ff7828aad5ee4282d0e6f844fd148d05d3c6ea251b)
Loading cached processed dataset at /home/utsav/.cache/huggingface/datasets/snli/plain_text/1.0.0/1f60b67533b65ae0275561ff7828aad5ee4282d0e6f844fd148d05d3c6ea251b/cache-0436d94218380653.arrow
(549367,
{'premise': 'A person on a horse jumps over a broken down airplane.',
'hypothesis': 'A person is training his horse for a competition.',
'label': 1})
Next we look at the distribution of lenghts(from a sample) of premise and hypothesis to choose the max_length we want to restrict our tokenizer to.
|
|
100%|██████████████████████████████████████████████████████████████549367/549367 [00:28<00:00, 19413.23it/s]
|
|
|
|
CPU times: user 2min 8s, sys: 1min 37s, total: 3min 46s
Wall time: 1min 30s
Now we will create out custom dataset and dataloaders with train/validation split for training.
|
|
|
|
CPU times: user 48.2 s, sys: 1.06 s, total: 49.3 s
Wall time: 49.2 s
|
|
|
|
{'premise_input_ids': tensor([[ 101, 1037, 2312, ..., 0, 0, 0],
[ 101, 1037, 2158, ..., 0, 0, 0],
[ 101, 1037, 2158, ..., 0, 0, 0],
...,
[ 101, 1037, 21294, ..., 0, 0, 0],
[ 101, 6001, 1998, ..., 0, 0, 0],
[ 101, 1037, 2316, ..., 0, 0, 0]]),
'premise_attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]]),
'hypothesis_input_ids': tensor([[ 101, 1996, 2111, ..., 0, 0, 0],
[ 101, 1037, 2158, ..., 0, 0, 0],
[ 101, 1037, 2711, ..., 0, 0, 0],
...,
[ 101, 1037, 21294, ..., 0, 0, 0],
[ 101, 6001, 1998, ..., 0, 0, 0],
[ 101, 2093, 2111, ..., 0, 0, 0]]),
'hypothesis_attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]]),
'label': tensor([0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0])}
Model config
Here we will setup out custom SBERT model as detailed in the diagram from the paper.
|
|
'cuda'
The method mean_pool() implements the mean token pooling strategy mentioned in the paper. The implementation has been picked up from the sentence_transformers library.
We will use the encode() method to compute pooled embeddings using the finetuned and the bert-base models later to evaluate the results on STS tasks.
|
|
|
|
|
|
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertModel: ['cls.seq_relationship.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.seq_relationship.weight']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
|
|
|
|
Training loop
|
|
|
|
Training ...
step 0/27469, loss = 1.108
step 1600/27469, loss = 0.621
step 3200/27469, loss = 0.453
step 4800/27469, loss = 0.540
step 6400/27469, loss = 0.633
step 8000/27469, loss = 0.598
step 9600/27469, loss = 0.308
step 11200/27469, loss = 0.669
step 12800/27469, loss = 0.595
step 14400/27469, loss = 0.710
step 16000/27469, loss = 0.502
step 17600/27469, loss = 0.339
step 19200/27469, loss = 0.350
step 20800/27469, loss = 0.324
step 22400/27469, loss = 0.572
step 24000/27469, loss = 0.699
step 25600/27469, loss = 0.494
step 27200/27469, loss = 0.555
Validating ...
step 0/6868, loss = 0.652
step 1600/6868, loss = 0.215
step 3200/6868, loss = 0.391
step 4800/6868, loss = 0.281
step 6400/6868, loss = 0.355
CPU times: user 52min 10s, sys: 26min 29s, total: 1h 18min 39s
Wall time: 1h 18min 35s
|
|
(0.5563077898345832, 0.4604906574972126)
Normally we look at losses over multiple epochs, but here we have only 1 epoch. One way to look at the mini batch losses is to use a running mean(smoothing) to reduce noise from per batch loss.
|
|
|
|
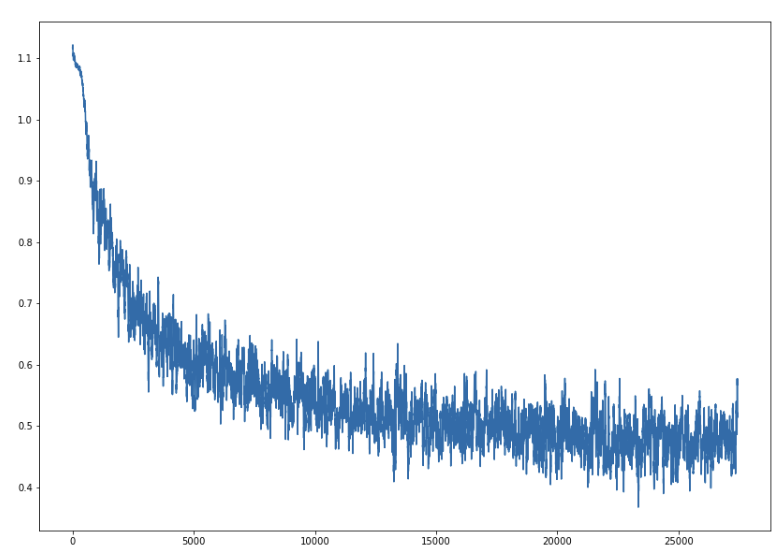
|
|
Evaluation
Here we will manually inspect the performance of our finetuned model as well as use a STS dataset for evaluation on a similar task as mentioned in the paper.
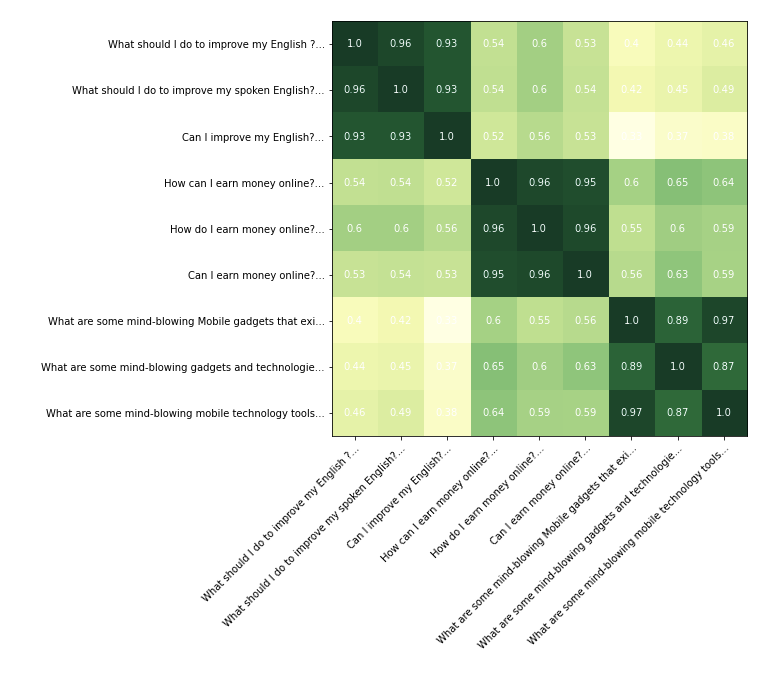
For manual inspection, we have taken few texts which fall neatly into three clusters. We want to see how neatly our finetuned model(and the bert-base model) is able to find these clusters.
|
|
|
|
|
|
Our finetuned model .
|
|
Next we import the original bert-base model again for comparison.
|
|
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertModel: ['cls.seq_relationship.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.seq_relationship.weight']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
|
|
|
|
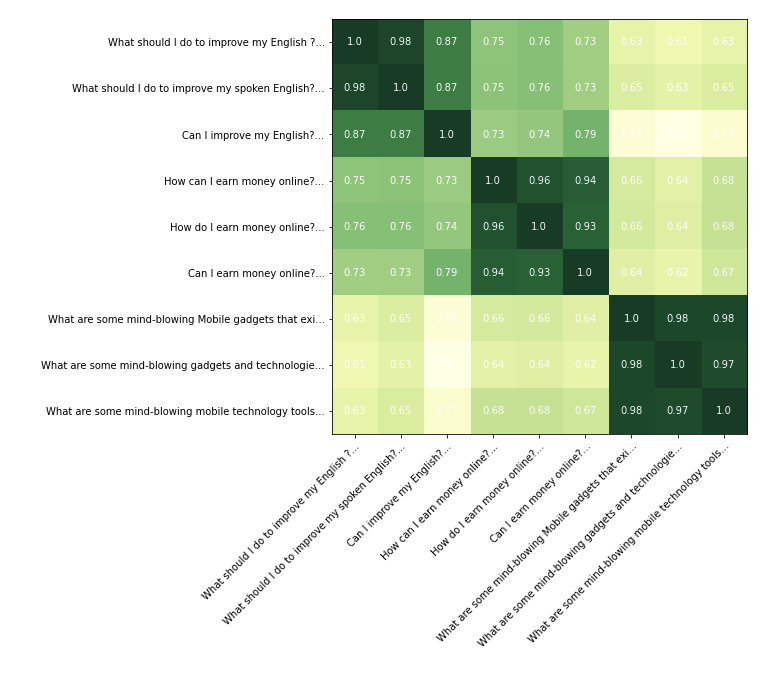
On a visual inspection we can see that both the models are doing a good job in finding the text clusters. The model we finetuned is doing a better job at pushing down the scores in the dissimilar clusters. The original bert-base model is scoring pretty much every pair of text above 0.6.
Let’s evaluate the models on a STS dataset.
|
|
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertModel: ['cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.decoder.weight']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
|
|
Reusing dataset glue (/home/utsav/.cache/huggingface/datasets/glue/stsb/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
(1500,
{'sentence1': 'A man with a hard hat is dancing.',
'sentence2': 'A man wearing a hard hat is dancing.',
'label': 5.0,
'idx': 0})
|
|
|
|
|
|
|
|
SpearmanrResult(correlation=0.7674179904574383, pvalue=1.7844520619824385e-291)
|
|
SpearmanrResult(correlation=0.5931769556210932, pvalue=3.0261969816970313e-143)
Our finetuned model is doing much better than the bert-base model on STS task with a spearman rank coorelation of .76 vs .59.
References
[1] Lena Voita. “https://lena-voita.github.io/nlp_course/word_embeddings.html"
[2] Nils Reimers, Iryna Gurevych. “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks”
[3] James Briggs. “https://www.pinecone.io/learn/train-sentence-transformers-softmax/"