IR in it’s most basic form answers the question “how relevant is a given query for a document”. The challenge is that we don’t have just 1 document but potentially millions or billions of documents. So the key challenge is - how can we efficiently find this “needle in the haystack” or the “relevant documents for a query”.
Here, document refers to any kind of text document, typically these could be web pages, emails, plain text documents, etc. There are many technicalities to consider in real world applications of IR like cleaning up the markup in case of web pages. The documents could also be in different languages, encodings, etc. These variations present their own unique sets of challenges. For example, it’s common to build separate pre-processing text pipelines for each language.
Relevance
To answer the question “how relevant is a given query for a document”, we first need to precisely define relevance.
Relevance in the context of queries and documents captures the following key ideas:
- A query can consist of many words, we break the query down into these individual words using a text processing pipeline which we will cover later.
- If a word appears more often in a document, it’s more relevant. We can capture this by counting the words in a document .
- If a document is longer, words will tend to appear more often. So we need to take the document length into account as well.
- It would be pretty slow if we start counting the words in all the documents after a query arrives, hence we need to store the counts in a data structure that supports efficient lookups for a query.
Inverted Index
An inverted index helps us solve the last point we mentioned under Relevance, “It would be pretty slow if we start counting the words in all the documents after a query arrives, hence we need to store the counts in a data structure that supports efficient lookups for a query.”
Inverted index allows us to efficiently retrieve documents from large collections. It does this by storing term/word statistics from the documents beforehand(that the scoring model needs).
The statistics stored in the inverted index are:
- Document frequency: How many documents contain the term.
- Term frequency per document: How often does the term appear in a document.
- Document length
- Average document length
The statistics are saved in a format that is accessible by a given term/word.

The term frequencies are stored in a “posting list” which is nothing but a list of document id and term frequency pairs. Every document gets an internal document id; which can be a simple integers for non web-scale data.
Creating the Inverted Index
The process of creating the inverted index involves creating a text processing pipeline which is applied both the documents as well as incoming queries.
A typical pipeline looks like: Tokenization -> Stemming -> Stop words removal.
Tokenization
Tokenization essentially involves splitting the query or document into individual terms/words. A naive baseline could split each query/document by whitespace and punctuation character. Improvements over the naive model typically involves keeping the abbreviations, names, numbers together as one token, etc. For example, look at the stanford tokenizer.
$ cat >sample.txt
"Oh, no," she's saying, "our $400 blender can't handle something this hard!"
$ java edu.stanford.nlp.process.PTBTokenizer sample.txt
``
Oh
,
no
,
''
she
's
saying
,
``
our
$
400
blender
ca
n't
handle
something
this
hard
!
''
PTBTokenizer tokenized 23 tokens at 370.97 tokens per second.
Stemming
Stemming involves reducing the terms/words to their “roots” before indexing. An advanced form of stemming called Lemmatization involves reducing the inflectional/variant forms to base form (am, are, is -> be). Lemmatization is computationally expensive.
For grammatical reasons, documents are going to use different forms of a word, such as organize, organizes, and organizing. Additionally, there are families of derivationally related words with similar meanings, such as democracy, democratic, and democratization. In many situations, it seems as if it would be useful for a search for one of these words to return documents that contain another word in the set.
The goal of both stemming and lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form. For instance:
am, are, is -> be,car, cars, car's, cars' -> car. The result of this mapping of text will be something like:the boy's cars are different colors -> the boy car be differ colorHowever, the two words differ in their flavor. Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes. Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma . If confronted with the token saw, stemming might return just s, whereas lemmatization would attempt to return either see or saw depending on whether the use of the token was as a verb or a noun. The two may also differ in that stemming most commonly collapses derivationally related words, whereas lemmatization commonly only collapses the different inflectional forms of a lemma. Linguistic processing for stemming or lemmatization is often done by an additional plug-in component to the indexing process, and a number of such components exist, both commercial and open-source.
The most common algorithm for stemming English, and one that has repeatedly been shown to be empirically very effective, is Porter’s algorithm (Porter, 1980).
Source: Stemming and lemmatization
Stop word removal
This simply involves removing the most common words that appear across all the documents. Typically, articles and pronouns are generally classified as stop words. Stop words play no significance in the scoring algorithms used for classic IR hence we remove them.
For example, “a”, “the”, “there”, etc.
Search and Relevance Scoring
Search workflow
The search workflow typically involves:
- Passing the query through the pre processing pipeline we just discussed to get the terms.
- Look up the statistics for each term from the inverted index.
- Use a scoring model that uses the term statistics to score the documents.
- Sort the documents by the scores in a descending order and show to the user.
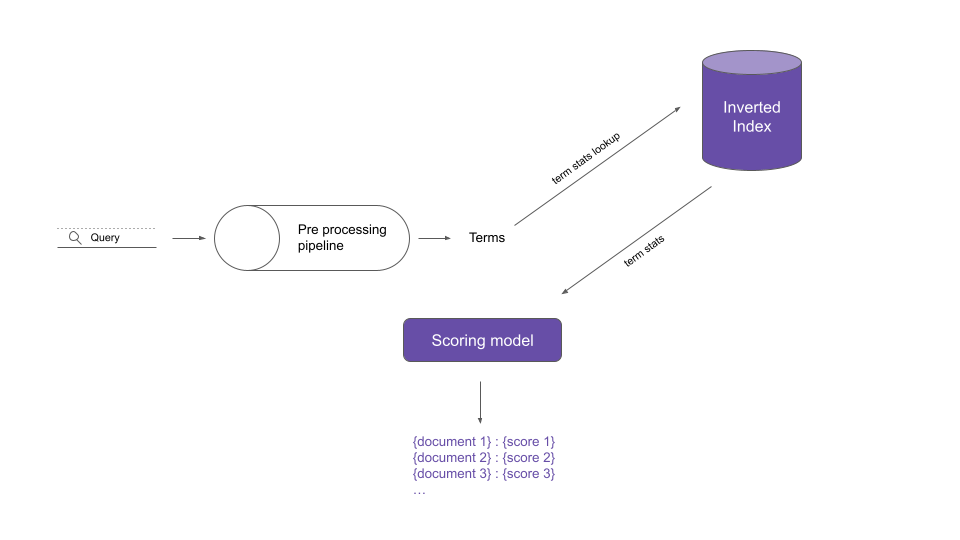
Note that a document could be relevant without containing the exact query terms. This is the biggest drawback of the classic IR techniques we are discussing here.
Dense retrieval techniques which we will cover later help us address this problem.
Types of queries
Once the query has been broken into individual words, there are many ways they can be used to fetch statistics from the inverted index:
- Exact matching: Match full words or concatenate multiple query words with “or”.
- Boolean queries: “and” / “or” / “not” operators between words.
- Expanded queries: Ddd synonyms and other similar words into the query.
Beyond this we can also augment the queries using wildcard queries, phonetic queries, etc.
Spell checking
Another way to improve the quality of retrieval is to use spell correctors to:
- Correct the documents being indexed.
- Correct user queries to retrieve correct documents - e.g. the google style “did you mean”.
Scoring models
The scoring model captures relevance in a mathematical model. Note that here we are only considering the free text queries here or “ad-hoc” document retrieval, other factors could also come into play in real life scenarios like pagerank, recency, click counts etc.
Another drawback of the scoring models we are about the discuss is the fact they don’t consider meaning of the terms. Terms/words are essentially just discrete symbols. Similarly documents are stream of meaningless symbols. The word order is not important as well.
Dense retrieval techniques which we will cover later help us address this problem.
TF_IDF
The TF_IDF has two components:
- Term Frequency tf(t,d): How often does the term t appear in the document d.
Using the raw frequencies here is not the best solution for IR problems. We either use relative frequencies or
logto dampen the frequenciestf(t,d) = log(1 + tf(t,d)). - Inverse Document Frequency idf(t): It’s a measure of the “informativeness” of a term for a document. Not that rare terms are more informative than frequent terms. Common way of defining IDF is
idf(t) = log(|D| / df(t)). Here|D|is the total number of documents anddf(t)is the number of documents in which the term t appears.
$$ TFIDF(q, d) = \sum_{t\in T_d \cap T_q} \log(1 + tf_{t,d}) * \log(\frac{\vert D \vert}{df_t}) $$
Where $\sum$ is the sum over all the terms in the query, $tf_{t,d}$ is the frequency of term t in document, ${\vert D \vert}$ is the total number of documents, ${df_t}$ is the number of documents in which the term t appears.
Beyond IR, TF_IDF is also used for other NLP tasks like finding keywords in a document, Latent Semantic Analysis(LSA), classification, etc.
Although the formulation in scikit-learn is not exactly the same, we can still look at TF_IDF in action.
|
|

For downstream ML tasks like classification(given we have the class labels), this matrix notation works perfectly. But computing, storing and updating this in matrix form for retrieval problems is not feasible due to the sparsity of this matrix for large number of documents.
For example, if we have 1m documents with average term length of 1000 and vocabulary size of 100k(pretty reasonable at scale), we end up with a matrix of size 1,000,000 x 100,000 of which ~1,000,000 x 90,000 or ~90% of the terms will be 0. Though this is a very conservative estimate, it makes it obvious that storing the TF_IDF for web scale data is not feasible in this format. We use inverted index we discussed earlier to store this info.
BM25 aka “BestMatch25”
BM25 is the backbone of most open source text based search engines over the last decade. It improves over the TF_IDF by taking into account the normalization of document length by average document length.
There are two hyperparameters k and b that can be tuned to define the influence of document length normalization.
$$ BM25(q, d) = \sum_{t\in T_d \cap T_q} \frac{tf_{t,d}}{k_1((1-b) + b\frac{dl_d}{avgdl})+tf_{t,d}} * \log(\frac{\vert D \vert - df_t + 0.5}{df_t + 0.5}) $$
Where $\sum$ is the sum over all the terms in the query, $tf_{t,d}$ is the frequency of term t in document d, ${dl_d}$ is the document length, ${avgdl}$ is the average document length, $\vert D \vert$ is the Total number of documents, ${df_t}$ is the number of documents in which the term t appears, ${k_1}$ and b are the hyperparameters.
Not that this formulation is simpler than the original formula. More complex parts related to query length have not much practical implications for IR. The key difference between TF_IDF vs BM25 is that the term frequency saturation is stronger in BM25.
The hyperparametrs:
- k: Controls term frequency scaling.
- b: Conrols the document length normalization.
Typical values of k and b are 1.2 < k < 2, 0.5 < b < 0.8.
There are other formulations of BM25 that take into account the title, abstract, headers etc. from the documents. We can essentially control the weights we want to assign to each component.
Oversimiplified implementation of the Inverted Index (TF_IDF)
|
|
|
|
Indexing ...
100 200 300 400 500 600 700 800 900
|
|
|
|
Score : 8.245
Document : ‘From: richg@sequent.com (Richard Garrett)\nSubject: Computers for sale ( PC and amiga )\nArticle-I.D.: sequent.1993Apr21.151726.26547\nDistribution: na\nOrganization: Sequent Computer Systems, Inc.\nLines: 57\nNntp-Posting-Host: crg8.sequent.com\n\nIts time for a little house cleaning after my PC upgrade. I have the following\nfor sale:\n\nLeading Technology PC partner (286) sytsem. includes\n\t80286 12mhz intel cpu\n\t85Mb IDE drive (brand new - canabalized from new system)\n\t3.5 and 5.24 f …
Score : 7.497
Document : “From: rosa@ghost.dsi.unimi.it (massimo rossi)\nSubject: ide &scsi controller\nOrganization: Computer Science Dep. - Milan University\nLines: 16\n\nhi folks\ni have 2 hd first is an seagate 130mb\nthe second a cdc 340mb (with a future domain no ram)\ni’d like to change my 2 controller ide & scsi and buy\na new one with ram (at least 1mb) that could controll \nall of them\nany companies?\nhow many $?\nand is it possible via hw or via sw select how divide\nthe ram cache for 2 hd? (for example usin …
Score : 6.218
Document : “From: lingeke2@mentor.cc.purdue.edu (Ken Linger)\nSubject: 32 Bit System Zone\nOrganization: Purdue University\nX-Newsreader: TIN [version 1.1 PL8]\nLines: 32\n\nA week or so ago, I posted about a problem with my SE/30: I have 20 megs\nor true RAM, yet if I set my extensions to use a large amount of memory\n(total of all extensions) then my system will crash before the finder\ncomes up. What I meant was having a large amount of fonts load, or\nsounds, or huge disk caches with a control panel …
Score : 5.523
Document : “From: ebosco@us.oracle.com (Eric Bosco)\nSubject: Windows 3.1 keeps crashing: Please HELP\nNntp-Posting-Host: monica.us.oracle.com\nReply-To: ebosco@us.oracle.com\nOrganization: Oracle Corp., Redwood Shores CA\nX-Disclaimer: This message was written by an unauthenticated user\n at Oracle Corporation. The opinions expressed are those\n of the user and not necessarily those of Oracle.\nLines: 41\n\n\nAs the subjects says, Windows 3.1 keeps crashing (givinh me GPF) on me …
Score : 5.356
Document : ‘From: afung@athena.mit.edu (Archon Fung)\nSubject: wrong RAM in Duo?\nOrganization: Massachusetts Institute of Technology\nLines: 9\nDistribution: world\nNNTP-Posting-Host: thobbes.mit.edu\n\nA few posts back, somebody mentioned that the Duo might crash if it has\nthe wrong kind (non-self refreshing) of RAM in it. My Duo crashes\nsometimes after sleep, and I am wondering if there is any software which\nwill tell me whether or not I have the right kind of RAM installed. I\nhad thought that the …
|
|
Score : 8.245
Document : ‘From: richg@sequent.com (Richard Garrett)\nSubject: Computers for sale ( PC and amiga )\nArticle-I.D.: sequent.1993Apr21.151726.26547\nDistribution: na\nOrganization: Sequent Computer Systems, Inc.\nLines: 57\nNntp-Posting-Host: crg8.sequent.com\n\nIts time for a little house cleaning after my PC upgrade. I have the following\nfor sale:\n\nLeading Technology PC partner (286) sytsem. includes\n\t80286 12mhz intel cpu\n\t85Mb IDE drive (brand new - canabalized from new system)\n\t3.5 and 5.24 f …
Score : 7.497
Document : “From: rosa@ghost.dsi.unimi.it (massimo rossi)\nSubject: ide &scsi controller\nOrganization: Computer Science Dep. - Milan University\nLines: 16\n\nhi folks\ni have 2 hd first is an seagate 130mb\nthe second a cdc 340mb (with a future domain no ram)\ni’d like to change my 2 controller ide & scsi and buy\na new one with ram (at least 1mb) that could controll \nall of them\nany companies?\nhow many $?\nand is it possible via hw or via sw select how divide\nthe ram cache for 2 hd? (for example usin …
Score : 5.523
Document : “From: ebosco@us.oracle.com (Eric Bosco)\nSubject: Windows 3.1 keeps crashing: Please HELP\nNntp-Posting-Host: monica.us.oracle.com\nReply-To: ebosco@us.oracle.com\nOrganization: Oracle Corp., Redwood Shores CA\nX-Disclaimer: This message was written by an unauthenticated user\n at Oracle Corporation. The opinions expressed are those\n of the user and not necessarily those of Oracle.\nLines: 41\n\n\nAs the subjects says, Windows 3.1 keeps crashing (givinh me GPF) on me …
Score : 5.236
Document : “Subject: XV under MS-DOS ?!?\nFrom: NO E-MAIL ADDRESS@eicn.etna.ch\nOrganization: EICN, Switzerland\nLines: 24\n\nHi … Recently I found XV for MS-DOS in a subdirectory of GNU-CC (GNUISH). I \nuse frequently XV on a Sun Spark Station 1 and I never had problems, but when I\nstart it on my computer with -h option, it display the help menu and when I\nstart it with a GIF-File my Hard disk turns 2 or 3 seconds and the prompt come\nback.\n\nMy computer is a little 386/25 with copro, 4 Mega rams, Ts …
Score : 4.705
Document : “From: Dale_Adams@gateway.qm.apple.com (Dale Adams)\nSubject: Re: HELP INSTALL RAM ON CENTRIS 610\nOrganization: Apple Computer Inc.\nLines: 23\n\nIn article C5115s.5Fy@murdoch.acc.Virginia.EDU \njht9e@faraday.clas.Virginia.EDU (Jason Harvey Titus) writes:\n> I had asked everyone about problems installing a 4 meg\n> simm and an 8 meg simm in my Centris 610, but the folks at the\n> local Apple store called the folks in Cupertino and found that\n> you can’t have simms of different speeds …
References
[1] Sebastian Hofstätter. “Advanced Information Retrieval 2021 @ TU Wien”